This study is based on an analysis of 12,832 sermons, homilies or worship services delivered between Aug. 31 and Nov. 8, 2020, and collected from the websites of 2,146 churches found via the Google Places application programming interface (API), a tool that provides information about establishments, geographic locations or points of interest listed on Google Maps. Pew Research Center data scientists collected these sermons between Nov. 12 and Dec. 21, 2020. The collection program used a machine learning model to identify webpages likely to contain sermons. It also used a set of specially designed algorithms to collect media files with dates from those pages, identify the files containing sermons, and transcribe those files for further analysis.
Researchers conducted this process on a sample of all churches found on Google Places. The sample was designed to ensure that researchers had enough cases to analyze sermons from smaller Christian traditions, including historically Black Protestant congregations. The list of churches is the same as the Center used in its 2019 study, meaning that new churches started since that time could not be included.
Here is a brief description of the main steps in the data collection process. Each is described in greater detail in corresponding sections of the methodology that follow.
Finding every church on Google Maps: Pew Research Center’s data scientists began by identifying every institution labeled as a “church” in the Google Places API, including each institution’s website (if it had one). This yielded an initial pool of 478,699 institutions. This list contained many non-congregations and duplicative records, which were removed in subsequent stages of the data collection process.
Determining religious tradition, size, and predominant race or ethnicity: The churches found via the Google Places API lacked critical variables like denomination, size or predominant racial composition. To obtain these variables, Center researchers attempted to match each church found on Google Places to a database of religious congregations maintained by InfoGroup, a targeted marketing firm. This process successfully matched 262,876 congregations and captured their denomination, size and racial composition – where available – from the InfoGroup database.
Identifying and collecting sermons from church websites: Data scientists deployed a custom-built software system (a “scraper”) to the websites of a sample of all churches in the initial dataset – regardless of whether they existed in the InfoGroup database – to identify, download and transcribe the sermons they share online. This program navigated to pages that appeared likely to contain sermons and saved every dated media file on those pages. Files dated between Aug. 31 and Nov. 8, 2020, were downloaded and transcribed. Researchers then coded a subset of these transcripts to determine whether they contained sermons and trained a machine learning model to remove files that did not contain sermons from the larger dataset.
Evaluating data quality: The resulting list of congregations with sermons online differs from congregations nationwide in critical ways, and is far smaller than the 478,699 institutions the Center initially found on Google Places. Of those congregations, 19,085 were selected to have their websites searched for sermons, and of that sample 2,143 made it into the final sermons dataset – meaning the scraper was able to successfully find and download sermons from their websites. Of the 2,143 churches in the final dataset, the Center was able to match 1,968 with variables derived from InfoGroup data, such as their religious tradition.
To properly contextualize these findings, researchers needed to evaluate the extent of these differences and determine the scraper’s effectiveness at finding sermons when they were present. To accomplish this, researchers manually examined the websites of 253 churches randomly sampled from the Center’s database in search of sermons, deployed the scraper to those same websites, and compared the results. The scraper successfully found 23% of all sermons (a large body of sermons were missed due to the Center’s lack of access to the YouTube API).
Classifying sermons by topic: Each sermon was divided into segments small enough for a researcher to read, and a subset of these segments was examined individually and coded (i.e., labeled) to indicate whether the pastor discussed the election, COVID-19 and racism in America. Researchers then trained machine learning classifiers to identify these topics across the whole database. Among sermons that discussed the election, researchers repeated this process to identify instances where a pastor encouraged congregants to vote, or discussed specific issues, candidates or parties.
Finding every church on Google Maps
To build a comprehensive database of U.S. churches, Center researchers designed an algorithm that exhaustively searched the Google Places API for every institution labeled as a “church” in the United States. At the time of searching, Google offered only search labels that hewed to specific groups, such as “church” or “Hindu temple.” As a result, researchers could not choose a more inclusive term and ultimately used “church” to cover the lion’s share of religious congregations in the U.S. Researchers used Google Places because the service provides websites for most of the institutions it labels as churches.
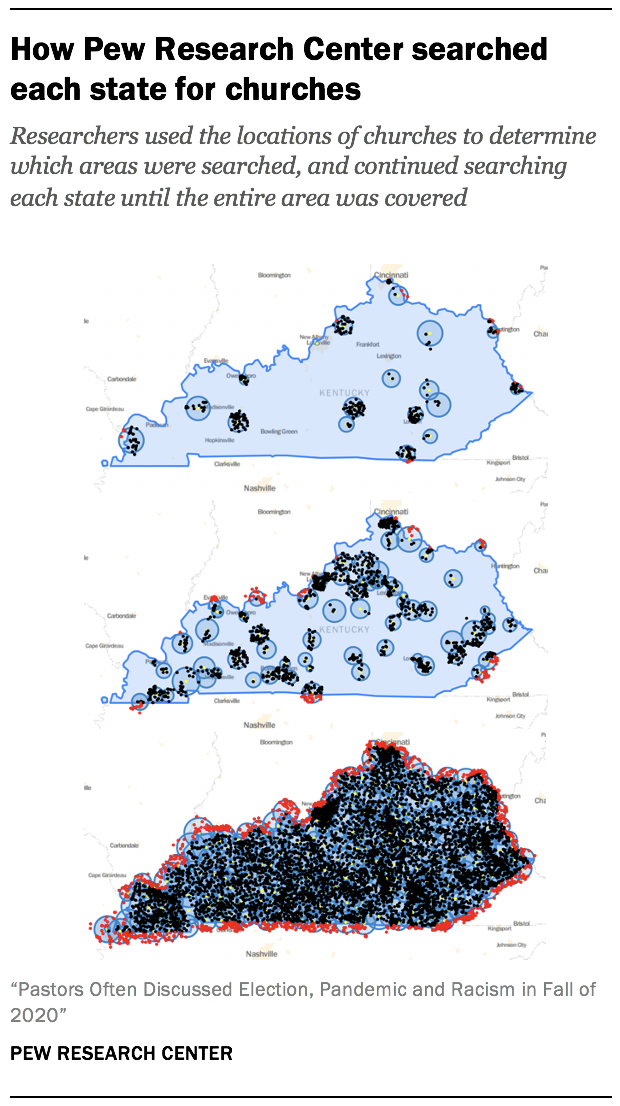 The program searched each state in the country independently. It began by choosing a point within the state’s area, querying the API for churches around that point, and then drawing a circle around those churches. The algorithm then marked off that circle as searched, began again with a new point outside the circle, and repeated this process until the entire state was covered in circles. Researchers dictated that results should all be returned in order of distance from the query point, regardless of other factors like prominence. This means that for each query, researchers could deduce that there were no omitted results closer to the center point of the query than the farthest result returned by the API.
The program searched each state in the country independently. It began by choosing a point within the state’s area, querying the API for churches around that point, and then drawing a circle around those churches. The algorithm then marked off that circle as searched, began again with a new point outside the circle, and repeated this process until the entire state was covered in circles. Researchers dictated that results should all be returned in order of distance from the query point, regardless of other factors like prominence. This means that for each query, researchers could deduce that there were no omitted results closer to the center point of the query than the farthest result returned by the API.
In practice, researchers could have used the farthest result to draw the coverage areas, but often used a closer one in an effort to be conservative.2 The algorithm relied on geographic representations of each state – called “shapefiles” – that are publicly available from the U.S. Census Bureau.
Researchers used a previous version of this algorithm in fall 2015 to collect an early version of the database. The early version of the algorithm was less precise than the version used in 2018, but compensated for that imprecision by plastering each area – in that case counties, not states – with dramatically more searches than were needed. The 2015 collection yielded 354,673 institutions, while the 2018 collection yielded 385,675. Researchers aggregated these two databases together for this study, counting congregations that shared the same unique identifier only once. Excluding these duplicates, the aggregated database included 478,699 institutions.
Determining religious tradition, size, and predominant race or ethnicity
This initial search process produced a comprehensive list of institutions labeled as churches on Google Places. But the resulting database contained almost no other information about these institutions – such as their denomination, size or predominant race or ethnicity. To acquire these variables, Center data scientists attempted to find each church listed in Google Places in an outside database of 539,778 congregations maintained by InfoGroup, a targeted marketing firm.
Researchers could not conduct this operation by simply looking for congregations in each database that shared the same name, address or phone number, because congregations may have names with ambiguous spellings or may change their addresses or phone numbers over time. A simple merging operation would fail to identify these “fuzzy” matches. To account for this ambiguity, human coders manually matched 1,654 churches from the Center’s database to InfoGroup’s, and researchers trained a statistical model to emulate that matching process on the remainder of the database.
The matching involved multiple stages:
1. Limiting the number of options coders could examine: As a practical matter, coders could not compare every church in the Center’s database to every church in InfoGroup’s. To reduce the number of options presented to each coder, researchers devised a set of rules that delineated what congregations in the InfoGroup database could plausibly be a match for any given record in the Center’s collection. This process is known as blocking.
For any given church in the Center’s database, the blocking narrowed the number of plausible matches from InfoGroup’s database to only those that shared the same postal prefix (a stand-in for region). Next, researchers constructed an index of similarity between each church in the Center’s database and each plausible match in the InfoGroup database. The index consisted of three variables summed together, each normalized to a 0-1 range. The variables were:
a. The distance in kilometers between each two churches’ GPS coordinates.
b. The similarity of their names, using the Jaro
c. The similarity of their addresses, using the Jaro-Winkler
These three variables were then summed together, and coders examined the 15 options with the greatest similarity values (unless two churches shared the same phone number and postal prefix, in which case they were always presented to the coders as an option regardless of their similarity value). In the rare event that there were fewer than 15 churches in a postal prefix area, coders were presented all churches in that postal area.
2. Manually choosing the correct match for a sample of churches: A group of five coders then attempted to match a sample of 2,900 congregations from the Center’s database to InfoGroup’s. In 191 cases where coders were unsure of a match, an expert from the Center’s religion team adjudicated. Overall, coders successfully matched 1,654 churches. Researchers also selected a sample of 100 churches to be matched by every coder, which researchers used to calculate inter-rater reliability scores. The overall Krippendorf’s Alpha between all five coders was 0.85, and the individual coders’ alpha scores – each judged against the remaining four and averaged – ranged from 0.82 to 0.87.
3. Machine learning and automated matching: As noted above, this process generated 1,654 matches between the two datasets. It also generated 41,842 non-matches (each option that the coders did not choose was considered a non-match). Center researchers used these examples to train a statistical model – a random forest classifier in Python’s scikit-learn – that was then used to match the remaining churches in the collection.
Researchers engineered the model to have equal rates of precision (the share of items identified as a match that were truly matches) and recall (the share of true matches that were correctly identified as such). This means that even while there was an error rate, the model neither overestimated nor underestimated the true rate of overlap between the databases. The model’s average 5-fold cross-validated precision and recall were 91%, and its accuracy (the share of all predictions that were correct) was 99%.
To apply the model to the remaining data, researchers had to replicate the blocking procedure for all 478,699 churches in the Center’s database, presenting the model with a comparable number of options to those seen by the coders. Researchers also calculated several other variables for use in the model that coders did not have access to, but in which the model might find statistical value.
The model’s features (variables) were: the distance between each pair of churches; the ranked distance between each pair (whether each was the closest option, the second closest, etc.); the similarity of their names using the Jaro distance; the similarity of their addresses using the Jaro-Winkler distance; a variable denoting whether they shared the same phone number; and one variable each for the most commonly appearing words from church names in the Pew Research Center database, denoting the cumulative number of times each word appeared across both names.
Center data scientists applied this model to each church in the Center’s database, successfully identifying a match for 262,876 in the InfoGroup database. For each matched church, researchers merged the congregation’s denomination, predominant race or ethnicity, and number of members into the database, where these variables were available.
Once the Center merged these variables into the database, researchers categorized InfoGroup’s religious groups into one of 14 groups: evangelical Protestant, mainline Protestant, historically Black Protestant, Catholic, Orthodox Christian, Mormon, Jehovah’s Witness, other Christian, Jewish, Muslim, Hindu, Buddhist, other faiths, and unclassifiable.
Protestant congregations with identifiable denominations were placed into one of three traditions – the evangelical tradition, the mainline tradition or the historically Black Protestant tradition. For instance, all congregations flagged as affiliated with the Southern Baptist Convention were categorized as evangelical Protestant churches. All congregations flagged as affiliated with the United Methodist Church were categorized as mainline Protestant churches. And all congregations flagged as affiliated with the African Methodist Episcopal Church were categorized as churches in the historically Black Protestant tradition.
In some cases, information about a congregation’s denominational affiliation was insufficient for categorization. For example, some congregations were flagged simply as “Baptist – other” (rather than “Southern Baptist Convention” or “American Baptist Churches, USA”) or “Methodist – other” (rather than “United Methodist” or “African Methodist Episcopal”).
In those instances, congregations were placed into categories in two ways. First, congregations were categorized based on the Protestant tradition that most group members identify with. Since most Methodists are part of mainline Protestant churches, a Methodist denomination with an ambiguous affiliation was coded into the mainline Protestant category. Second, if the congregation was flagged by InfoGroup as having a mostly African American membership (and the congregation could potentially be considered historically Black Protestant) the denomination was categorized in the historically Black Protestant group.
For example, congregations flagged simply as “Baptist – other” were coded as evangelical Protestant congregations (since most U.S. adults who identify as Baptist are affiliated with evangelical denominations, according to the 2014 U.S. Religious Landscape Study), unless the congregation was flagged as having a mostly African American membership, in which case it was placed in the historically Black Protestant tradition. Similarly, congregations flagged as “Methodist – other” were coded as mainline congregations (since most U.S. adults who identify as Methodist are affiliated with mainline Protestant denominations), unless the congregation was flagged as having a mostly African American membership, in which case it was placed in the historically Black Protestant tradition.
Complete details about how denominations were grouped into traditions are provided in the appendix to the Center’s 2019 report “The Digital Pulpit.”
Identifying and collecting sermons from church websites
Although the database now contained a list of church websites along with data about the characteristics of each congregation, the Center was faced with the challenge of identifying and collecting the sermons posted by these churches online. Researchers designed a custom scraper – a piece of software – for this task. The scraper was designed to navigate through church websites in search of files that appeared to be sermons, download them to a central database and transcribe them from audio to text if needed.
Sampling and weighting
Rather than scrape every church website in the database – which would have taken a great deal of time while offering few statistical benefits – Center researchers scraped the websites of a sample of the entire database. The sample was drawn to ensure adequate representation of each major Christian tradition, as well as congregations that did not match to InfoGroup, for which the Center did not have a tradition or denomination. The Center assigned each record in the database to one of seven strata. The strata were:
- Catholic
- Historically Black Protestant
- Mainline Protestant
- Evangelical Protestant
- Unclassifiable, due to limitations with available data
- Not matched to InfoGroup
- Other – an umbrella category including Buddhist, Mormon, Jehovah’s Witness, Jewish, Muslim, Orthodox Christian, Hindu, other Christian or other faiths. (This category was not analyzed on its own, because the original search used only the term “church.”)
Researchers then drew a random sample of up to 2,428 records from each stratum, except for historically Black Protestant congregations, of which researchers sample all available congregations to ensure a large enough sample of sermons to analyze.
This pool of sampled records was then screened to distinguish between multi-site congregations that shared a website and duplicative records, so that duplicative ones could be removed. This was done using the following procedure:
- First, researchers removed churches that were found only in the first Google Maps collection (see Google Maps section for more details).
- After that, any records with a website that appeared more than five times in the database were excluded on the grounds that these were likely to include denominational content, rather than that of individual congregations.
- For any remaining records with matching websites, researchers took steps to identify and remove duplicate records that referred to the same actual congregation. Two records were considered to be duplicates if they shared a website and met any of the following criteria:
- Both records were matched to the same congregation in the InfoGroup database.
- Both records had the same street address or census block.
- One of the two records lacked both a phone number and a building number in its address.
In any of these three instances, the record with the highest match similarity (as measured by the certainty of the matching model) to InfoGroup or, if none matched to InfoGroup, the most complete address information was retained. Congregations that shared a street address but had different websites were not considered to be duplicates but rather distinct congregations that happened to meet in the same location.
The end result was a sample of 19,085 distinct congregations distributed as follows: evangelical (2,428), Catholic (2,428), mainline (2,428), unclassifiable (2,428), unmatched (2,428), historically Black Protestant (4,517), and an agglomerated “small groups” category (2,428). These congregations were then weighted to once more represent their prevalence in the database.
Any statistics stating the share of sermons that mention a topic have a margin of error between 2.8% and 4%. And any statistics stating the share of all congregations hearing at least one sermon that mentions a topic have a margin of error ranging from 4.4% to 5.8%. (These statistics represent the full range of the margin of error, meaning the appropriate confidence interval is plus or minus half the amount reported here.)
It is important to note that the estimates in this report are intended to generalize only to the population of churches with websites that were in the original database, and not the entire population of all Christian churches in the United States (which also includes churches that do not have a website or were not listed in Google maps at the time the database was constructed).
How the scraper worked
 Researchers made some early decisions about how the scraper should identify sermons:
Researchers made some early decisions about how the scraper should identify sermons:
- Every sermon, by definition, had to be associated with a date on the website where it was found. This date was interpreted as its delivery date, an interpretation that generally held true.
- Sermons had to be either hosted on the church’s website, or shared through a service, such as Vimeo, that was directly linked from that church’s website. This was to ensure we did not incorrectly assign a sermon to a church where it was not delivered. Sermons shared solely on YouTube channels were not included in this report due to increased restrictions on the YouTube API.
- A sermon had to be hosted in a digital media file, rather than written directly into the contents of a webpage. This is because the scraper had no way of determining whether text written into a webpage was, or was not, a sermon. These files could consist of audio (such as an MP3 file), text (such as a PDF), or video (such as a YouTube link).
Identifying sermons involved two main steps: determining which pages to scrape, and then finding media files linked near dates on those pages. These files – digital media files, displayed near dates, on pages likely to contain sermons – were then transcribed to text if needed, and non-sermons were removed.
Determining which pages to examine
How we trained a model to identify pages with sermons
To identify pages likely to contain sermons, researchers trained a machine learning classifier – a Linear Support Vector Machine – on pages identified by coders as having sermons on them. In September 2018, coders examined a sample of church websites and identified any links that contained sermons dated between July 8 and Sept. 1, 2018. Coders also examined a random sample of links from these same websites and flagged whether or not the links contained any sermons; most of them did not. Taken together, a set of 906 links was compiled from 318 different church websites, 412 of which were determined to contain sermons and 494 of which did not. Using these links, a classifier was trained on the text of each link, along with any text that was associated with the links for those that had been identified by the scraper. Researchers stripped all references to months out of the text for each link before training the model, so it would not develop a bias toward pages containing the words “July,” “August” or “September.”
The model correctly identified pages with sermons with 0.86 accuracy, 0.86 precision (the share of cases identified as positive that were correct), and 0.83 recall (the share of positive cases correctly identified). Researchers calculated these statistics using a grouped 5-fold cross validation, where links from the same church were not included in both the test and training sets simultaneously.
To ensure the scraper navigated to the correct pages, researchers trained a machine learning model that estimated how likely a page was to contain sermons. The model relied on the text in and around a page’s URL to make its estimate. In addition to the model – which produced a binary, yes-or-no output – the scraper also looked on church webpages for key words specified by researchers, such as “sermon” or “homily.”
Based on a combination of the model’s output and the keyword searches, pages were assigned a priority ranging from 0-4. The scraper generally examined every page with a priority above zero, and mostly did so in order of priority.
Finding dated media files on pages flagged for further examination
Once the scraper determined that a page was at least somewhat likely to contain sermons, it visited that page and examined its contents in detail in search of files matching the search criteria described above. In some cases, sermons were housed in a protocol such as RSS – a common format for podcasts – that is designed to feed media files directly to computer programs. In those cases, the sermons were extracted directly, with little room for error. The same was true for sermons posted directly to Vimeo accounts.
But in most cases, sermons were embedded or linked directly within the contents of a page. Although these sermons might be easy for humans to identify, they were not designed to be found by a computer. The scraper used three main methods to extract these sermons:
1. Using the page’s structure: Webpages are mostly written in HTML, a language that denotes a page’s structure and presentation. Pages written with HTML have a clearly denoted hierarchy, in which elements of the page – such as paragraphs, lines or links – are either adjacent to or nested within one another. An element may be next to another element – such as two paragraphs in a block of text – and each also may have elements nested inside them, like pictures or lines.
The scraper searched for sermons by examining every element of the page to determine if it contained a single human-readable date in a common date format, as well as a single media file.3
2. Using the locations of dates or media files: In the event that the scraper could not identify a single element with one date and one media file, it resorted to a more creative solution: finding every date and every media file on the page, and clustering them together based on their locations on a simulated computer screen.
In this solution, the scraper scanned the entire page for any media files – using a slightly more restrictive set of search terms – and any portions of text that constituted a date.4 The scraper then calculated each element’s “x,y” coordinates, using screen pixels as units. Finally, each media file was assigned to its closest date using their Euclidean distance, except in cases where a date was found in the URL for the page or media file itself, in which case that date was assumed to be the correct one.
3. Using only the text of the media files: Finally, the scraper also scanned the page for any media files that contained a readable date in the text of their URLs. These were directly saved as sermons.
In addition to the above rules that guided the scraper, researchers also placed some restrictions on the program. These were designed to ensure that it did not endlessly scrape extremely large websites or search irrelevant parts of the internet:
- Researchers did not allow the scraper to examine more than five pages from a website other than the one it was sent to search. This rule allowed for limited cases where a church may link to an outside website that hosted its sermons, but prevented the scraper from wandering too far afield from the website in question and potentially collecting irrelevant data.
- There were three cases in which the scraper stopped scraping a website before it had examined all of the pages with priorities above zero: 1) if it had examined more than 100 pages since finding any new sermons; 2) if it had been scraping the same website for more than 10 hours, or 3) if the scraper encountered more than 50 timeout errors.
- Some pages were explicitly excluded from being examined. These mainly included links to common social media sites such as Twitter, links to the home page of an external website, or media files themselves, such as MP3 files.
- The scraper always waited between two and seven seconds between downloading pages from the same website to ensure scraping did not overburden the website.
Finally, the scraper removed duplicative files (those found by multiple methods).
Validation and cleaning of scraped files
Researchers conducted a number of steps at various stages of the data collection to clean and validate the scraped files, and to convert them to a machine-readable format that could be used in the subsequent analysis. These steps are described in more detail below.
Removing non-sermons from the collected list of media files
Although the initial scraping process collected dated media files from pages likely to contain sermons, there was no guarantee that these files actually contained sermons. To address this problem, researchers tasked a team of human coders with examining 200 transcribed files – randomly sampled from the database – to determine whether they contained sermons or not. Researchers then trained an extreme gradient boosting model (using the XGBoost package in Python) machine learning model on the results, and used that model to remove non-sermons from the remainder of the database. The model achieved 91% accuracy, 93% recall and 92% precision.
In classifying the files used to train the machine learning model, coders were instructed to consider as a sermon any religious lesson, message or teaching delivered by anyone who appears to be acting as a religious leader in an institution that is at least acting as a religious congregation. They were instructed to not include anything that was clearly marked as something other than a sermon (such as a baptism video, Sunday school lesson or religious concert). Sermons with specific audiences (such as a youth sermon) were classified as sermons. In contrast to the Center’s 2019 study of online sermons, messages specifically designed for an online audience were included in the study if they otherwise met the Center’s definition of a sermon.
In determining who qualified as a religious leader, coders could not use the age, gender or race of the speaker, even if there was a reasonable justification for doing so (for instance, a White pastor in a historically Black Protestant denomination, or a woman preaching in a church that ordains only men). Coders were instructed to classify any files that included a sermon along with any other content (such as a song, prayer or reading) as a sermon.
Downloading and transcription
The sermons in the collection varied dramatically in their formatting, audio quality and complexity. Some were complete with podcast-style metadata, while others were uploaded in their raw format. The downloading system attempted to account for this variability by fixing common typographical errors, working around platform-specific formatting or obfuscation, and filling in missing file extensions using other parts of the URL or response headers where possible. Any sermon for which the encoding could be read or guessed was then saved.
Once retrieved, PDFs and other text documents were converted to transcripts with minimal processing using open-source libraries. Multimedia sermons were processed using the FFmpeg multimedia framework to create clean, uniform input for transcription. Video sermons occasionally included subtitles or even different audio streams. When multiple audio streams were available, only the primary English stream was extracted; when an English or unlabeled subtitle stream was available, the first such stream was stored as a distinct type of transcript, but the audio was otherwise handled similarly.
Before transcription could be performed, the extracted media files were normalized to meet the requirements of the transcription service, which imposed constraints on file encoding, size and length. Researchers transcoded all files into the lossless FLAC format and split them into chunks if the file exceeded the service’s duration limit. AWS Transcribe returns complex transcripts, including markup that defines each distinct word recognized, the timestamps of the start and end of the word, and the level of confidence in the recognized word.
Evaluating data quality
Evaluating the scraper’s performance
To evaluate the scraper’s performance, Center researchers manually examined the websites of a random sample of 253 congregations. Each website was assigned a randomly chosen one-week window within the study period, and researchers identified all sermons within that week. The scraper was then deployed to these same websites, and researchers determined whether it had found each sermon identified by researchers.
Of the 128 sermons found by researchers on these NCS church websites, the scraper correctly identified 29. This means the system correctly identified, downloaded and transcribed 23% of all sermons shared on the websites of churches in the database. This relatively low number is partially explained by the fact that the Center was unable to access the YouTube API for this study – of the 128 sermons found by coders, 55 (43%) were shared on YouTube. While some of these may have been directly embedded on church websites – in which case the scraper could find them – many would have been shared only on YouTube channels.
The Center does not view these performance statistics as validating or invalidating the contents of the research. Rather, they are intended to help the reader understand the nature of this limited but interesting window into American religious discourse.
Classifying sermons by topic
To determine whether a sermon discussed any given topic, researchers used machine learning models trained on hand-labeled data. However, any given sermon was generally too long for a researcher to read in one sitting. To address this, researchers divided each sermon into 250-word segments, which were then labeled for each topic of interest. Researchers trained machine learning classifiers (specifically, a distilbert base uncased classifier from the HuggingFace package in Python) to identify each topic. In identifying each topic, every document was coded separately by two coders, and any disagreements were adjudicated by an expert. All performance statistics are based on fivefold cross-validation.
The specific questions answered by coders, any necessary coding notes and the model’s performance statistics are as follows:
- The 2020 election:
- Question: “Does this mention the fall 2020 elections, including any references to presidential or congressional candidates, voting, or American political parties?”
- Precision: 0.86, recall: 0.85
- The COVID-19 pandemic:
- Question: “Does this mention the COVID-19 pandemic, including prevention measures?” (Coders were instructed not to count instances where the speaker referenced the immediate logistics of holding a service during the pandemic, for instance reminding parishioners to maintain distance in their seats).
- Precision: 0.71, recall: 0.70
- Racism in America:
- Question: “Does the speaker mention racism or racial inequity?”
- Precision of 0.76, recall: 0.74
Among congregations that discussed the election, researchers trained two more classifiers to identify cases where pastors encouraged congregants to vote, and where pastors discussed specific issues, parties or candidates. Those classifiers performed as follows:
- Parties, issues or candidates:
- Question: “Does the speaker discuss political candidates, parties, or policy issues?” (Only references to candidates, parties or policies in U.S. politics were counted).
- Precision and recall: 0.79
- Encouragement to vote:
- Question: “Does the speaker explicitly encourage listeners to vote, talk about how they should vote, or speak positively towards voting in a way that clearly encourages it?” (An example of the latter case would be telling listeners to “celebrate their right to vote.”)
- Precision: 0.74, recall: 0.72
Data anomaly during model application
After training and applying the machine learning models, but before beginning analysis, researchers discovered a small number of sermons that appeared twice across the database. Many of these were sermons that were posted twice by the same congregation in different formats – for instance, in both video and audio format. These duplicates were simply removed during analysis; however, a small number of duplicate sermon segments remained in the data while researchers were training the classification models. In the case of the main topics – the election, COVID-19, and racism in America – a single sermon segment appeared twice in the training data out of the 1,356 documents used to train the classifiers. In the case of the subtopics examined within discussion of the election, three duplicates appeared out of 599 examples.
Duplicative data could, in theory, inflate a classifier’s performance statistics in the event the same document appeared in a training and test set. However, researchers assessed that such a small number of duplicates could not have impacted model performance in any substantial way.
Classifying congregations by religious tradition
Researchers developed a methodology for using the religious denomination information provided by InfoGroup to classify congregations into the major categories (Christian “traditions”) used by the Center for analysis. For a full enumeration of how groups were classified, see this appendix from the Center’s 2019 report, “The Digital Pulpit.”
© Pew Research Center, 2021
