Media coverage of President Donald Trump and his administration is based on data collected from Jan. 21 to April 30, 2017. This time frame begins the day following the inauguration of Trump and includes all weekdays through his 100th day in office. The study is not an analysis of media bias or evaluating whether the coverage of Trump and his administration was accurate or fair.
This study was conducted in two parts: the main analysis and a secondary, comparative analysis. The main analysis studied stories about the president and his administration from a set of digital and broadcast news media (the primary sample). In order to compare across administrations, the comparative analysis pulled stories from a limited set of outlets for a shorter time period (the comparison sample).
Sample design
Primary sample
The primary sample incorporated news stories from a selection of broadcast outlets, digital native news sites and the digital presence of broadcast outlets and print newspapers. The selection criteria for each platform are described below, along with the sampling method for qualifying stories from each outlet.
For this project, qualifying stories were defined as stories that were at least 50% about Trump and/or his administration. Specified editorial or opinion sections or segments were not included, but individual opinion stories not set apart in a designated opinion section were included.
Broadcast
Outlet selection
News content was collected and studied from the television broadcasts of the three primary cable news networks (FOX, CNN, MSNBC), three major commercial broadcast networks (ABC, CBS, NBC), PBS, and radio broadcasts of NPR and the two highest rated talk radio hosts according to Talkers.com (Rush Limbaugh and Sean Hannity). In all cases, the first 30 minutes of selected programs (defined below), Monday through Friday, were screened for qualifying stories.
Cable
Cable news programming draws its largest audience in prime time. Researchers studied the four news programs on each cable network between 7 p.m. and 11 p.m.5 Shows were rotated such that two shows from each cable network were included in the sample on each weekday.
Network nightly news
Researchers studied weeknight programming from ABC, CBS, NBC, and PBS. Only episodes from every second day were included in this analysis, and at least one network’s news show was included each weekday.
Radio
Within radio, every episode of Rush Limbaugh and The Sean Hannity Show was included in the sample. For NPR, Morning Edition and All Things Considered were rotated such that one was included each day. Radio broadcasts were recorded from online streams using automated tools. In the case where shows were accidentally not recorded, or the streams were pre-empted for other programming (although the show itself was still produced), researchers used alternate recordings.6 For Limbaugh and Hannity radio programs, researchers used podcasts, while for the NPR shows researchers used the daily archive of the show on each program’s website.
Story selection
Individual segments from each show’s sample were selected as follows: First, a trained team of coders identified all story segments within the first 30 minutes of a program that focused primarily (at least 50%) on Trump or the administration’s actions and policies. Every third story from each coded day was then selected for inclusion, and the starting story was also rotated each day (i.e., one day would start with the first story about Trump or the administration, the next with the second, etc.). Segments that were shorter than 30 seconds were not included in this study.
Outlets and shows included in the broadcast component of the primary sample:
Network
ABC World News Tonight
NBC Nightly News
CBS Evening News
PBS NewsHour
Cable
CNN
- The Situation Room with Wolf Blitzer (5 p.m.)
- Erin Burnett OutFront (7 p.m.)
- Anderson Cooper 360 (8 p.m.)
- CNN Tonight with Don Lemon (10 p.m.)
Fox News Channel
- The First 100 Days (7 p.m.)
- The O’Reilly Factor (8 p.m., canceled 4/21)
- Tucker Carlson Tonight (9 p.m., moved to 8 p.m. on 4/24)
- Hannity (10 p.m.)
MSNBC
- Hardball with Chris Matthews (7 p.m.)
- All In with Chris Hayes (8 p.m.)
- The Rachel Maddow Show (9 p.m.)
- The Last Word with Lawrence O’Donnell (10 p.m.)
Radio
- The Sean Hannity Show
- The Rush Limbaugh Show
- Morning Edition (NPR)
- All Things Considered (NPR)
Digital content
Outlet selection
Digital natives
Digital native websites were selected via a process similar to that used for the 2017 Pew Research Center State of the Media report, which uses comScore data to determine the average monthly audience of outlets. Unique visitors from November 2016 through March 2017, which were acquired from the comScore Media Metrix database for Total Digital Population, were used to determine a site’s inclusion in the study. To be included, a site needed to receive 20 million average unique monthly visitors in November-December 2016 and at least 15 million in the first quarter of 2017.
Researchers then examined the resulting sites to determine if they produced original content. This led to a list that included several technology, sports, and culture sites that during the time period did not extensively report on political issues. Accordingly, researchers performed a site search (a search limited to the site domain) on Google for each site to get a sense of the amount of political coverage on each site. There were two steps to this process: First, researchers conducted a Google site search for pages with the word “the” as a control word to get a sense of the overall number of pages on the site. Second, these results were compared with a similar search for “Obama” (who was still in office at the time sampling decisions were first made) and those sites for which less than 10% of pages contained the word Obama compared to the control word were excluded.
The digital native sites included were:
- Breitbart
- Business Insider
- BuzzFeed
- Huffington Post (renamed to HuffPost April 25, 2017)
- Independent Journal Review (IJR)
- International Business Times (IB Times)
- Politico
- Slate
- Vox
Digital content of print newspapers
Five print newspapers were selected for study, based on their top tier circulation ranking (according to the Alliance for Audited Media) that focused daily coverage on national affairs. Researchers then verified that the websites of these five legacy newspapers had traffic of at least 20 million average monthly unique visitors in November-December 2016 and 15 million in the first quarter of 2017 using comScore data.
The included newspapers were:
- USA Today
- The New York Times
- The Washington Post
- The Wall Street Journal
- Los Angeles Times
Digital content of broadcast outlets
Researchers verified that the digital presence for the broadcast outlets identified above had traffic of at least 20 million average monthly unique visitors in November-December 2016 and 15 million in the first quarter of 2017 using comScore data. The digital presence of nearly all broadcast outlets met these criteria, with the websites of MSNBC, Rush Limbaugh and Sean Hannity being the only exceptions. Digital content for these three outlets was not included.
Story selection
The number of stories selected from each outlet was determined by comScore traffic. Two stories per weekday were selected from outlets whose websites received more than 50 million average monthly unique visitors from November 2016-March 2017, and one story per weekday was selected from sites below 50 million average monthly unique visitors during this time period (the number of stories per weekday for each outlet is noted below).
The outlets from which two digital stories were coded were: Business Insider, BuzzFeed, CNN, Fox News, Huffington Post, The New York Times, USA Today and The Washington Post. The outlets from which one digital story was coded were: ABC News, Breitbart, CBS News, NBC News, IBTimes, IJR, Los Angeles Times, NPR, Politico, Slate, Vox and The Wall Street Journal.
Each day’s home page was used to select stories; home pages were drawn from snapshots that were taken at 9 a.m., 2 p.m., and 9 p.m. (all times Eastern) each day and the snapshots used were rotated among those times (e.g., one day may use 9 a.m. and the next 2 p.m.). These snapshots were collected using automated methods; across all sites, researchers wrote scripts to record the HTML and screenshot of the front pages of each site at each of the times above.
The most prominent stories (in terms of where they appear on the home page) that focused on the Trump administration (at least 50% about Trump or his administration) were selected for analysis. Stories that were shorter than 100 words were not included in this study.
The primary sample had a total of 3,013 stories.
Comparison sample
The comparison sample duplicates for 2017 the samples used in other Pew Research Center studies conducted on the beginning of the Clinton, Bush and Obama presidencies. This sample consisted of seven media outlets – two newspapers, one news magazine and four broadcasts – in order to replicate these previous studies. The 2017 time period was Jan. 21 to March 21, 2017. This covers the first 60 days of Trump’s presidency, excluding inauguration day, in line with these previous studies.
The specific outlets, selected to develop a sample of coverage provided by the national press, are as follows:
Newspapers
The New York Times
The Washington Post
Weekly magazine
Newsweek
Evening network TV
ABC World News Tonight
CBS Evening News
NBC Nightly News
PBS NewsHour
Newspaper stories were drawn from section front pages (i.e., national news, style, business, metro, Sunday review), editorials and op-ed pieces. In prior years, complete newscasts and complete issues of Newsweek were the basis for the sample of television and magazine stories. In 2017, there was generally much more content related to the presidency, so a random sample of content was drawn from the coverage, excluding weekends. The resulting sample had 326 stories. The 2009 sample had 362 stories, the 2001 sample had 333 stories and the 1993 sample had 566 stories.
Human coding of stories
The data in this study were created by a team of four coders who were trained specifically for this project.
The central variables in this study were:
- Topic refers to the general subject matter of the story. For every story, each paragraph was assigned a topic, and the overall topic assigned to the story was the one that was the most common. There were a total of 44 different topics, which are grouped below into the three broad topic categories used throughout the analysis – domestic issues, foreign affairs issues and personal/political issues:
- Domestic issues – Abortion/family planning, agriculture, budget/taxes, business/economy, campaign finance, civil rights/liberties, crime incident or trends, crime/gun policy, culture/arts, defense (U.S. domestic), disasters, education, election process, environment, health care, immigration, labor, poverty, religion, science/technology, women’s rights, Social Security, energy, media, other domestic issues
- Foreign affairs – Foreign trade, Iraq War/Iraq generally, Afghanistan War/Afghanistan generally, Iran, China, U.S.-Russia relations, North Korea, Syria, European Union/NATO, international institutions (other), Israel/Palestine, international terrorism, Middle East (other), other foreign issues
- President’s management and political approach – Personal profile/character, appointments/nominations, political skills, political philosophy/ideology
- Other
- Frame refers to what the journalist is evaluating the president and his administration on. This study classified stories into one of two main frames: a) the president’s leadership and character or b) his core ideology and policy agenda. For every story, each paragraph was assigned a frame, and the overall frame assigned to the story was the one that accounted for a majority of the paragraphs.
- Source type refers to a person, group, organization or publication cited in a story. Citations included direct or indirect quotes, interviews, attributions or references accompanying factual information. With this in mind, researchers coded for the presence of nine different source types. Within each story, a source type was coded only once, even if it was cited repeatedly. The nine source types were:
- Trump or a member of the administration
- The Trump organization or a family member
- Congressional Democrat
- Congressional Republican
- Issue-based group or interest group
- Expert
- Poll
- Other journalist or news organization
- Citizen
- Assessment of the Trump administration refers to a story’s overall tone toward the president and the administration’s actions or words. The evaluation measure is tied to the frame of the story – either leadership and character or core ideology and policy agenda. Each statement (made by a source or the reporter him or herself) in a story was analyzed as to whether it carried a positive, negative or neutral assessment of the president and his administration. Within a story, there needed to be at least twice as many positive as negative statements for a story to be considered positive, and vice versa to be considered negative. Otherwise stories were coded as neither positive nor negative.
- Trigger refers to the action, event or editorial decision for which a news story was created. In other words, this captures the impetus for that story to be published on that particular occasion. Stories were categorized as being initiated by:
- Trump/administration
- Congressional Republican or Democrat
- Other government (includes federal agencies, the Supreme Court, congressional hearings, local and state government actors, and other political figures who are not currently in office)
- Economy
- Trump organization/family
- News media
- Planned political event
- Unplanned external event
- Foreign government
- Other outside actor
- Poll
- Other
- Refutation of Trump or the administration refers to any instance in which the journalist directly refuted or invalidated a statement made by Trump or a member of his administration. This included instances in which the journalist provided evidence for these claims and those in which no evidence was provided. Judgments about performance, personality or policy without any direct refutation were not included.
Coders were given multiple sets of news stories from each platform type to evaluate during the training period. Once internal agreement on how to code the variables was established, coding of the content for the study began. The Krippendorf Alpha estimate for each variable is below. For each variable, this estimate is based on a minimum of 132 stories and upwards of 201 stories.
- Topic: 0.74
- Frame: 0.65
- Source type: 0.68 or higher (average is 0.81)
- Assessment of the Trump administration: 7 0.63
- Trigger: 0.70
- Refutation of Trump or the administration: 0.71
Throughout the coding process, staff discussed questions as they arose and arrived at decisions under supervision of the content analysis team leader. In addition, the master coder checked coders’ accuracy throughout the process.
Grouping of outlets by ideological composition of their audience
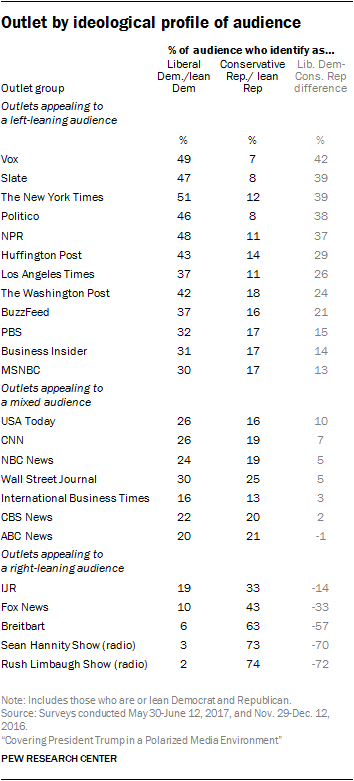 Each outlet was grouped according to the ideological composition of its audience. This grouping was based on the ratio of the proportion of the audience of each outlet who self-identifies as a liberal Democrat (including independents who lean Democrat) to the proportion that identifies as a conservative Republican (including independents who lean Republican).
Each outlet was grouped according to the ideological composition of its audience. This grouping was based on the ratio of the proportion of the audience of each outlet who self-identifies as a liberal Democrat (including independents who lean Democrat) to the proportion that identifies as a conservative Republican (including independents who lean Republican).
Data were drawn from a pair of surveys conducted Nov. 29-Dec. 12, 2016, and May 30-June 12, 2017, each asking about a different set of outlets (for a summary of each survey’s design, see below). The first survey asked respondents if they regularly got news about the 2016 presidential election from each outlet. The second asked if they regularly got news about politics from each outlet. Researchers then calculated each outlet’s audience ratio based on the self-identified party identification and political ideology of each respondent. An outlet is considered to have a left-leaning audience if the proportion of all audience members that identify as liberal Democrats is at least two-thirds higher than the proportion that identify as conservative Republicans. Alternatively, an outlet is considered to have a right-leaning audience if the proportion of all audience members that identify as conservative Republicans is at least two-thirds higher than the proportion that identify as liberal Democrats. And an outlet with a more mixed audience is one in which neither liberal Democrats nor conservative Republicans make up at least two-thirds more of the audience than the other.
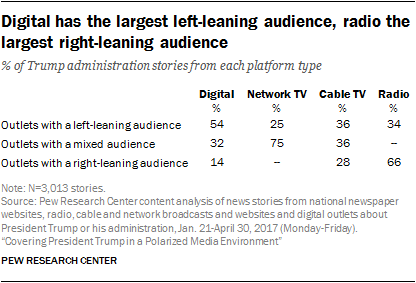 Looking at the sources by platform, more than half (54%) of the digital content was from outlets with a left-leaning audience. Radio content, on the other hand, was dominated by outlets appealing to a right-leaning audience (66%). Content from cable TV was more evenly split among audience types, while network nightly TV content was dominated by more mixed-audience outlets (75% of all content).
Looking at the sources by platform, more than half (54%) of the digital content was from outlets with a left-leaning audience. Radio content, on the other hand, was dominated by outlets appealing to a right-leaning audience (66%). Content from cable TV was more evenly split among audience types, while network nightly TV content was dominated by more mixed-audience outlets (75% of all content).
Survey design
Data in this report for outlet groupings are drawn from two surveys. The first was from a wave of the American Trends Panel (ATP), conducted from Nov. 29 to Dec. 12, 2016, among 4,183 respondents. The margin of sampling error for the full sample of 4,183 respondents is plus or minus 2.7% percentage points. The American Trends Panel, created by Pew Research Center, is a nationally representative panel of randomly selected U.S. adults recruited from landline and cellphone random-digit-dial surveys. Panelists participate via monthly self-administered web surveys. Panelists who do not have internet access are provided with a tablet and wireless internet connection. The panel is being managed by Abt Associates.
Members of the American Trends Panel were recruited from two large, national landline and cellphone random-digit-dial (RDD) surveys conducted in English and Spanish. At the end of each survey, respondents were invited to join the panel. The first group of panelists was recruited from the 2014 Political Polarization and Typology Survey, conducted from Jan. 23 to March 16, 2014. Of the 10,013 adults interviewed, 9,809 were invited to take part in the panel and a total of 5,338 agreed to participate.8 The second group of panelists was recruited from the 2015 Survey on Government, conducted from Aug. 27 to Oct. 4, 2015. Of the 6,004 adults interviewed, all were invited to join the panel, and 2,976 agreed to participate.9
The ATP data were weighted in a multistep process that begins with a base weight incorporating the respondents’ original survey selection probability and the fact that in 2014 some panelists were subsampled for invitation to the panel. Next, an adjustment was made for the fact that the propensity to join the panel and remain an active panelist varied across different groups in the sample. The final step in the weighting uses an iterative technique that aligns the sample to population benchmarks on a number of dimensions. Gender, age, education, race, Hispanic origin and region parameters come from the U.S. Census Bureau’s 2014 American Community Survey. The county-level population density parameter (deciles) comes from the 2010 U.S. Decennial Census. The telephone service benchmark comes from the July-December 2015 National Health Interview Survey and is projected to 2016. The volunteerism benchmark comes from the 2013 Current Population Survey Volunteer Supplement. The party affiliation benchmark is the average of the three most recent Pew Research Center general public telephone surveys. The internet access benchmark comes from the Center’s 2015 Survey on Government. Respondents who did not previously have internet access are treated as not having internet access for weighting purposes. The frequency of internet use benchmark is an estimate of daily internet use projected to 2016 from the 2013 Current Population Survey Computer and Internet Use Supplement. Sampling errors and statistical tests of significance take into account the effect of weighting. Interviews are conducted in both English and Spanish, but the Hispanic sample in the American Trends Panel is predominantly native born and English speaking.
The November 2016 wave had a response rate of 79% (4,183 responses among 5,280 individuals in the panel). Taking account of the combined, weighted response rate for the recruitment surveys (10.0%) and attrition from panel members who were removed at their request or for inactivity, the cumulative response rate for the wave is 2.6 %.10
The data for the outlet groupings in this report is also drawn from a nationally representative survey conducted from May 30-June 12, 2017 among a sample of 4,024 adults 18 years of age or older. The margin of error for the full sample is plus or minus 1.6 percentage points.
The survey was conducted by the GfK Group in English and Spanish using KnowledgePanel, its nationally representative online research panel. KnowledgePanel members are recruited through probability sampling methods and include those with internet access and those who did not have internet access at the time of their recruitment (KnowledgePanel provides internet access for those who do not have it, and if needed, a device to access the internet when they join the panel). A combination of random-digit dialing (RDD) and address-based sampling (ABS) methodologies have been used to recruit panel members (in 2009 KnowledgePanel switched its sampling methodology for recruiting members from RDD to ABS).
KnowledgePanel continually recruits new panel members throughout the year to offset panel attrition as people leave the panel. All active members of the GfK panel were eligible for inclusion in this study. In all, 6,667 panelists were invited to take part in the survey. All sampled members received an initial email to notify them of the survey and provide a link to the survey questionnaire. Additional follow-up reminders were sent to those who had not responded as needed.
The final sample of 4,024 adults was weighted using an iterative technique that matches gender, age, race, Hispanic origin, education, region, household income, home ownership status and metropolitan area to the parameters of the Census Bureau’s March 2016 Current Population Survey (CPS). This weight is multiplied by an initial sampling or base weight that corrects for differences in the probability of selection of various segments of GfK’s sample and by a panel weight that adjusts for any biases due to nonresponse and noncoverage at the panel recruitment stage (using all of the parameters described above).
Sampling errors and statistical tests of significance take into account the effect of weighting at each of these stages. In addition to sampling error, one should bear in mind that question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
