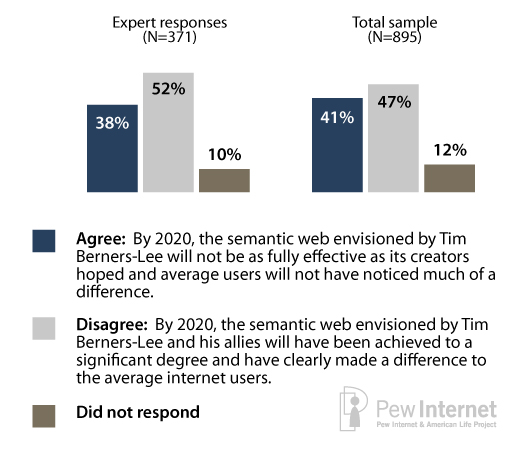
Overview of responses
Background
Sir Tim Berners-Lee, the inventor of the World Wide Web, has an even grander vision for what the web can be. He and his allies have been working through the World Wide Web Consortium on an evolving initiative they call the semantic web. Berners-Lee and co-authors wrote in Scientific American in 2001 that they see a future when machines can understand data and make meaningful connections between related items, all in the service of helping people get the material they want and complete the tasks that matter to them:
-
The semantic web will bring structure to the meaningful content of Web pages, creating an environment where software agents roaming from page to page can readily carry out sophisticated tasks for users… The semantic web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation… To date, the Web has developed most rapidly as a medium of documents for people rather than for data and information that can be processed automatically. The semantic web aims to make up for this… The real power of the semantic web will be realized when people create many programs that collect Web content from diverse sources, process the information and exchange the results with other programs.
In the article, Berners-Lee and co-authors James Handler and Ora Lassila sketched out a scenario of how the semantic web would work and highlighted the keywords which indicate terms whose semantics, or meaning, were defined for the computer “agent” through the Semantic Web:
-
The entertainment system was belting out the Beatles’ “We Can Work It Out” when the phone rang. When Pete answered, his phone turned the sound down by sending a message to all the other local devices that had a volume control. His sister, Lucy, was on the line from the doctor’s office: “Mom needs to see a specialist and then has to have a series of physical therapy sessions. Biweekly or something. I’m going to have my agent set up the appointments.” Pete immediately agreed to share the chauffeuring.
At the doctor’s office, Lucy instructed her Semantic Web agent through her handheld Web browser. The agent promptly retrieved information about Mom’s prescribed treatment from the doctor’s agent, looked up several lists of providers, and checked for the ones in-plan [eligible for insurance coverage] for Mom’s insurance within a 20-mile radius of her home and with a rating of excellent or very good on trusted rating services. It then began trying to find a match between available appointment times (supplied by the agents of individual providers through their Web sites) and Pete’s and Lucy’s busy schedules.
In a few minutes the agent presented them with a plan. Pete didn’t like it—University Hospital was all the way across town from Mom’s place, and he’d be driving back in the middle of rush hour. He set his own agent to redo the search with stricter preferences about location and time. Lucy’s agent, having complete trust in Pete’s agent in the context of the present task, automatically assisted by supplying access certificates and shortcuts to the data it had already sorted through. Almost instantly the new plan was presented: a much closer clinic and earlier times—but there were two warning notes. First, Pete would have to reschedule a couple of his less important appointments. He checked what they were—not a problem. The other was something about the insurance company’s list failing to include this provider under physical therapists: “Service type and insurance plan status securely verified by other means,” the agent reassured him. “(Details?)”
Lucy registered her assent at about the same moment Pete was muttering, “Spare me the details,” and it was all set. (Of course, Pete couldn’t resist the details and later that night had his agent explain how it had found that provider even though it wasn’t on the proper list.)
The Wikipedia entry on the semantic web elaborates the idea this way: “The semantic web is a vision of information that is understandable by computers, so computers can perform more of the tedious work involved in finding, combining, and acting upon information on the web.” In his 1999 book “Weaving the Web,” Berners-Lee said: “I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A ‘semantic web’, which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ‘intelligent agents’ people have touted for ages will finally materialize.”
People commonly refer to the semantic web as the next generation of the World Wide Web – or, sometimes. Web 3.0. The hope is that it might improve data aggregation to such an extent over the next decade that an internet search that now yields hundreds or thousands or millions of responses (many not associated with the searcher’s needs) will generally deliver only the specific information she seeks.
The concept is so revolutionary that people have difficulty describing it in just so many words and its proponents self-consciously struggle to describe the “killer app” for the semantic web that will make users understand its power – and support its creation. Berners-Lee describes it as “getting one format across applications” so the semantic web standards can enable people to gain access to the information they want and use it any way they want, for instance, being able to mesh data from a personal bank statement and a personal calendar. He has said he would like to see a future web that allows people to connect their ideas with the ideas of others, building a system for people to share parts of ideas in a way that can make them whole.
Success for the semantic web will depend upon people working together to accept its standards (GRDDL, RDFa, OWL, SPARQL, and others) and its naming and tagging ontologies. Sites already implementing semantic web elements include DBpedia, Twine, Garlik, GeoNames, RealTravel, and MetaWeb.
The semantic web has some vocal opponents and critics. One is blogger, author, and speaker Cory Doctorow who described in a 2001 essay titled, “Metacrap: Putting the Torch to Seven Straw-Men of the Meta-topia” what he considered to be the seven obstacles to getting reliable data: People are lazy; people cannot accurately observe themselves; people lie; people are stupid; schema are not neutral; metrics influence results; and there’s more than one way to describe something.
Another critic is author, blogger, and professor Clay Shirky. In a 2003 column titled, “The Semantic Web, Syllogism, and Worldview” he wrote, “The semantic web is a machine for creating syllogisms…despite their appealing simplicity, syllogisms don’t work well in the real world because most of the data we use is not amenable to such effortless recombination …. There is a list of technologies that are actually political philosophy masquerading as code, a list that includes Xanadu, Freenet, and now the semantic web … like many visions that project future benefits but ignore present costs, it requires too much coordination and too much energy to effect in the real world, where deductive logic is less effective and shared worldview is harder to create than we often want to admit.”
Shirky did concede, however, that some positive results will come from the efforts made toward creating a semantic web.
Accompanying the hopes for the semantic web and other Internet development are fears about the future of privacy and identity and the need for security in an architecture in which growing amounts of information are shared in a worldwide data cloud. For instance, security is vital for companies and individuals who employ semantic web products and technologies. When search for aggregated data becomes more specific, a simple search for a person’s name can yield health records, parking tickets, mortgages, signatures, travel records, video-viewing habits, and any other recordable, databased information. People’s Web-search histories, financial transactions, mailing lists, and surveillance photography of them and their homes are being collected and can be accessed, forming a “digital shadow” for every individual and group on record.
Respondents’ thoughts
With that all as background, here are some of the major themes that emerged in the answers to our survey:
Too many complicated things have to fall into place for the semantic web to be fully realized. The idea is a noble one and gives the technology community something to shoot for. But there is too much variation among people and cultures and economic competitors to allow for such a grand endeavor to come to fruition.
- “There will be more and better meta-information, but it will continue to be opportunistic, siloed, and ad hoc in 2020.” –Susan Crawford, founder of OneWebDay, Internet law professor at the University of Michigan, former special assistant in the Obama administration for Science, Technology and Innovation Policy; http://scrawford.net/blog/about/
- “Life is messy. So’s the internet.” –Jeff Jarvis, author of “What would Google Do?”, associate professor and director of the interactive journalism program and the new business models for news project at the City University of New York’s Graduate School of Journalism; http://www.buzzmachine.com/about-me/
- ”Alas, the semantic web is an idea that owes more to the desires of computing scientists and information theorists for a world of perfected knowledge and processed reason than to reality. The semantic web is like the Encyclopaedia of the Modern project: an ideal whose existence enables us to make progress but that can never be achieved because it fails to account for the cultural malleability of knowledge, the political economy of information, and – ultimately – the agency of humans, with their machines, in subverting the ideals of pure reason to the partial ends of personal gain.” –Matthew Allen, director of the department of Internet Studies at the School of Media, Culture and Creative Arts, Curtin University of Technology, and critic of social uses and cultural meanings of the Internet; http://www.netcrit.net/
- “The semantic web depends on cooperation by commercial vendors, and what we have seen most often is not cooperation but rather selfish and non-sharing behaviour. Look at Apple, for example, which has its own proprietary stack for the iPhone. Or Facebook, which consumes data, but only in very rare cases shares it. Where the semantic web will be most effective will be in informal, non-commercial and underground activities – but in this environment the rigid formality that characterizes the semantic web cannot be enforced. Instead, we will get a roughly interoperative polyglot, as characterized, for example, by RSS. From time to time these will surface and become widespread, breaking the commercial companies’ proprietary monopoly. But it will be an ongoing struggle, and semantic web applications will struggle to become mainstream.” –Stephen Downes, senior research officer, National Research Council of Canada, and specialist in online learning, new media, pedagogy and philosophy; http://www.downes.ca/me/index.htm
- “It’s been a decade and everyone still says ‘semantic what?’ Do we really need another decade to figure this out?” —Stuart Schechter, Microsoft Research; http://research.microsoft.com/en-us/people/stus/
- “Semantic web is a lost cause. Berners-Lee looked at the landscape, picked out certain features, bundled them together and called it semantic web. But, unfortunately, to 99% of the population, the semantics of this term, i.e. the meaning of it, is a total mystery. As a result, nobody is demanding it, and it will not happen. However, some of the features that were bundled under this umbrella, will become more common, in certain contexts. Semantic web tried to boil the ocean, and failed, as one would expect.” –Michael Dillon, network consultant at BT and a career professional in IP networking since 1992, member of BT’s IP Number Policy Advisory Forum; http://uk.linkedin.com/pub/michael-dillon/4/663/4B
- “I don’t like answering this question in the negative, but I understand Berners-Lee’s concept of the semantic web as being more structured than the various collections of folksonomies and APIs that we have today, and I don’t foresee us progressing far in that direction in the coming 10 years. A more structured web can be enabled by enhancements to HTML, for example, but getting people to adopt those enhancements and use them consistently and regularly is another matter. There are also the issues of human language to be considered; linkages across languages will remain problematic. Even if a semantic web emerges for the English-language web, what about everyone else?” –Mindy McAdams, Knight Chair in journalism, University of Florida, author, “Flash Journalism: How to Create Multimedia News Packages,” journalist, http://mindymcadams.com/index.htm
- “Just as it is impossible to prevent slang, argot, and creoles from forming, so we will continue to demonstrate polymorphous perversity in our expression and knowledge production.” –Sandra Braman, professor in the Department of Communication, University of Wisconsin-Milwaukee, and expert on the macro-level effects of new information technologies; https://pantherfile.uwm.edu/braman/www/html/bio.html
- “The semantic web concept disregards the fundamental fuzziness and variability of human communication. It may allow us to cope with the huge quantity of information available in electronic form and may provide some initial order, but the latter won’t be any more effective than earlier knowledge organization systems have been. The proliferation of agents coupled with the lack of authority may indeed lead to much less effective results.” –Michel J. Menou, Ph.D, information science, independent consultant in ICT policy, visiting professor and associate researcher, School of Library, Archives and Information Services, University College London; http://slisweb.sjsu.edu/people/faculty/menoum/menoum.php
- “There is too much work involved on the part of website owners for the semantic Web to work. Various efforts to put more meta-data on web pages have not worked. It’s hard to see why the SW should be different.” –Peng Hwa Ang, dean of the School of Communication and Information, Nanyang Technological University, Singapore, and active leader in the global Internet governance processes of WSIS and IGF; http://www3.ntu.edu.sg/sci/about/profile_AngPengHwa.html
- “I love the semantic web, but I still see the construction costs being FAR too high to meet the lofty goals of TBL et al. Just look at the state of CMS [content management systems]. Well-built HTML is still a rarity, add on top of that the requirements of microformats, RDF, OWL, or similar techniques and it will only find practical applications within formalized information systems such as Wikipedia, IMDB, etc.” –Roarke Lynch, Director, NetSmartz Workshop for the National Center For Missing and Exploited Children
- “The key problem with the semantic web is the problem of false data and trust. I think it is a great idea in theory, and many of these principles of the semantic web will be more deeply integrated into the services we use, but an automated web-for-machines that automatically make better decisions for us because of the data they export is a pipedream.” –David Sifry, founder of Technorati and CEO of Offbeat Guides; http://www.sifry.com/alerts/about/
Forget the skeptics. The semantic web will take shape and launch an “age of knowledge.” Early successes will build momentum.
- “Within the next 10 years, the semantic web will take us from the age of information to the age of knowledge. Simple tools and services will allow individuals, corporations and governments to quickly glean meaning from the vast amounts of data they have compiled. This move from a ‘World Wide Web’ to a ‘world wide database’ will allow for hidden relationships and connections to quickly surface, driving both innovation and (unfortunately) exploitation. The impact of the semantic web will be substantial. It will help create new industries, influence campaign strategies and lead to ground-breaking discoveries in both science and medicine.” –Bryan Trogdon, president of First Semantic, http://www.ted.com/profiles/view/id/63628
- “Yes, but we won’t call it that… and, as in the second option, no one will notice.” –Esther Dyson, founder and CEO of EDventure, investor and serial board member, journalist and commentator on emerging digital technology; http://www.edventure.com/new-bio.html
- “It may not be implemented fully as envisioned, but the value of a semantic web will become transparent. Early successes will demonstrate its value leading others to experiment with semantic technology.” –Robert Cannon, senior counsel for Internet law at the US Federal Communications Commission; http://www.cybertelecom.org/cannon.htm
- “The establishment of the Web Science Trust is a key aspect of what is going on here. The web is coming of age, and the need for a new science is well understood. Tim [Berners-Lee] is driving this. It is a logical and evolutionary step that is being taken today, and builds upon the work he’s driven as well as catalysed in the semantic web and in Linked Data.“ –JP Rangaswami, chief scientist, British Telecommunications; http://uk.linkedin.com/in/jprangaswami
- “Developments continue all the time in finding ways to associate online content and retrieve patterns from them. Meaning will be increasingly extractable.” –Ron Rice, Ph.D, co-director of the Carsey-Wolf Center for Film, Television and New Media, University of California-Santa Barbara, divisional officer, International Communication Association and Academy of management; http://www.comm.ucsb.edu/faculty/rrice/bio.htm
- “When I think of the semantic web I think of ‘intelligent applications.’ These could be as simple as smarter web browsers and e-mail clients that can understand natural language instructions and complete more complex tasks like automatically booking flights for us, emailing friends and marking our calendars. It could also be systems that can process data from multiple linked sources and arrive at something new. Like a corporate system that evaluates the areas of expertise of its employees and recommends optimal project teams. Or a knowledge-management system that can tell you whether a particular idea you just thought of is already being worked on by someone else. The problem with the web today is that it’s mostly designed for people to understand. But the applications we use to make life easier all have a hard time making sense of information. The semantic web changes that.” –Chris Marriott, Acxiom Corporation and digital marketing advisor for the Association of National Advertisers
- “I’m saying yes to this one more because I wish it and hope for it than that I know or feel it to be the clear shape of things to come. I think we’re still at the beginning of the semantic Web. I hope that by 2020 it’s at least a healthy toddler.” –Joshua Freeman, director of interactive services, Columbia University Information Technology; http://www.linkedin.com/in/jfreeman
Improvements are inevitable, but they will not unfold the way Tim Berners-Lee and his allies have sketched out. They will be grassroots-driven rather than standards-driven. Data mining, links, analysis of social exchanges will help drive the process of smartening the web without more formal semantic apps.
- “I firmly believe that the web of 2020 will be substantially more semantic than it is today – but it won’t be the semantic web in the orthodox definition promoted by Berners-Lee et al. The trajectory of recent years (especially with the transition to ‘Web 2.0’) has been one of increased metadata generation, and those data can be harnessed as semantic information, of course – but they will continue to conform to their own, continually emerging and changing schemata rather than to a uniform semantic description language as the semantic web initiative postulates it. This need not make the semantic information available on the web any less useful or effective, however, as the tools for extracting and processing such non-standard metadata from the folksonomic jumble that is the web have also become more and more powerful – but it is a user-generated, semantic web from below rather than a well-ordered, well-structured semantic web from above. It’s the triumph of a Google-style ‘brute processing power’ approach to making sense of the Web over a Yahoo!-style ‘orderly ontologies’ approach, all over again.” –Axel Bruns, associate professor, Media & Communication, Queensland University of Technology and general editor of the journal Media and Culture; http://au.linkedin.com/in/snurb
- “Artificial intelligence will certainly accomplish many if not all of the goals of the semantic web, but I do not think that the semantic web is the right mechanism for helping computers truly understand the internet. The idea behind the semantic web is too artificial and makes too many false assumptions about the inputs.” –Hal Eisen, senior software engineering manager for Ask.com; http://www.linkedin.com/pub/hal-eisen/0/95/a24
- “My answer is misleading here, because I think semantic technologies are already having a huge impact, and will continue to develop and improve a host of areas in IT. However, the vision of Tim Berners-Lee and other SemWeb evangelists has often been unrealistic – not because of the tech but because of the human logistics and desires for control. Much of what they talked about (e.g., the dentist appt. example) will be addressed more effectively through social computing as much as semantic tech, and the two will be incrementally improved and integrated into IT workflows in such a manner that most users will never notice the improvement – it will just ‘work better’ and be seen as a natural evolution, rather than as a result of some particular technology.” –Patrick Schmitz, semantic services architect, University of California Berkeley
- “I think some form of next generation meta-web is inevitable, but it will probably take directions not envisioned by Berners-Lee or his cohorts. Evolution tends to be characterized by chaos, which trait makes it well nigh impossible to predict with any degree of certainty. Future technology has never really been very deterministic.” –Robert G. Ferrell, information systems security officer for the National Business Center of the U.S. Department of the Interior; http://www.theplinth.org/
- “Many will not bother to code their web pages the way the semantic Web proponents would like us to. Some sites may do this; others won’t bother. The internet will still be a wild west with a wide variety of content and quality and searchability.” –Peter Timusk, webmaster and Internet researcher, statistical products manager at Statistics Canada; http://ca.linkedin.com/in/petertimusk
- “I see a bigger impact from the ‘social web’ vs. the ‘semantic web’ due to the level of consumer generated content and random information that is posted. While we will have more ways to create content and read the content and will be more connected than ever before, it will be more social. The average user will continue to look to friends for recommendations for information – regardless of the form those come in and will, as humans do, trust their friends more than anything else.” –Elaine Young, associate professor, Champlain College; http://www.linkedin.com/in/elainejyoung
- “The problems facing the successful arrival of a semantic web are not simply technological, but lie in significant part in the human element itself. The nature of human-produced content makes it extremely difficult to categorise without loss of accuracy or reliability. In libraries there are certain requirements, and agreed formats, and even then it is necessary to blur lines and endure mistakes. It will take more than ten or eleven years for the human-produced content of the Internet to become compatible with the idea of a semantic Web. In considering semantic web, it is important to note that the sort of Internet envisioned by Tim Berners-Lee is quite different from the one we seem to be developing.” –Francis J.L. Osborn, philosopher, University of Wales-Lampeter
- “I don’t perceive that we have a long way to go before ‘semantic links’ become the norm. We don’t need systems that are fully intelligent; even dumb systems can appear to do semantic linkages such as matching ‘crimson’ to ‘red.’ Look at the music websites, such as Pandora, that are already moving in these directions.” – Karl Auerbach, chief technical officer at InterWorking Labs, Inc.; http://www.linkedin.com/in/karlauerbach
- “The semantic web will have had an effect, but it will not be the semantic web envisioned by Tim Berners-Lee, but a much more informal one, where meaning will be obtained more out of data mining and other statistical techniques. Also, it will have clearly made a difference to the average internet users, but most of them will not notice.” –César Córcoles, professor at the Universitat Oberta de Catalunya, Barcelona, Spain; http://obm.corcoles.net/
- “In 2020 we will have a semantic web, but it will be a bootstrapped one, that adapts to the immense amount of conversation flowing back and forth through the web.” —Fred Stutzman, Ph.D candidate, researcher and teaching fellow, School of Information and Library Science, UNC-Chapel Hill; http://fredstutzman.com/index.html
- “The semantic web is an overhyped set of standards for linking data. Sir Tim’s brilliant idea with the web was to create a single simple protocol for accessing a number of disparate kinds of data. The semantic web is not such a simple idea, but is instead a series of high marginal cost, frequently contestable ontologies and meta text mark-up. Its not bad, but nor is it simple. By contrast, the genius of Friendster was to call the links that people had online as ‘friend’s. No, they may not be real friends, but it is a workable metaphor. I parallel this innovation to the innovation of creating ‘http’: simple, uniform and emergent. So now compare the present success of social network sites based on the friend model (Facebook, MySpace, Orkut) to the Friend-of-a-Friend (FOAF) ontology. The latter is perhaps the most successful semantic web technology. It is has little over a million users. Half a billion people are on social network sites. The semantic web will be handy for increased categorization of data, but it will not represent a quantum leap forward in intelligibility for the end user. Collaborative filtering and machine learning style categorization of the emergent networks based on the simple friend model will make a difference, as will future advances in machine learning in general.” –Bernie Hogan, research fellow, Oxford Internet Institute, University of Oxford; http://people.oii.ox.ac.uk/hogan/
The timeline of this question is off. The semantic web is shaping up, but it will take longer than the 10 years the question cited.
- “By 2020, efficient ways to exchange structured data will definitely be in place and there will be more structure to all sorts of content, ranging from end-user generated content to online government data. Tim’s vision of the semantic web – however – means that pretty much everybody will have to upgrade their databases, content management systems and such to something that supports RDF and other W3C standards. Looking at the number of legacy systems that are in place today, *especially* in government, banking, transportation and other places that are highly important to this vision, I remain skeptical that this will happen within 10 years. Judging from what we’ve seen happen in the world of web services, where REST-ful interfaces are killing off heavier approaches such as XML-RPC and SOAP, we’ll probably see a bottom-up approach where a few, simpler methods will fulfill a smaller set of the sem-web vision.” –Hjalmar Gislason, founder and CEO of DataMarket; former director of business development at Iceland Telecom; http://is.linkedin.com/in/hjalli
- “I believe a semantic web will come, but 2020 is too early for it to have any significant effect. I don’t see how we could deploy the semantic Web in the large without significant behavioural changes, and it takes a decade or two for significant behavioural changes to take place. (Think of how long it took for e-mail to become widespread.) This is a very long process – a GOOD concept, but may be hard to generate adoption.” –Pekka Nikander, Ericsson visiting senior research scientist, Helsinki Institute for Information Technology, chief scientist, Ericsson Research Nomadiclab; http://fi.linkedin.com/pub/pekka-nikander/0/43/b98
- “The adoption curve for semantic web will be longer than we’d (or I’d) like. This is a technology that needs a critical mass in order to fully realize its potential. I don’t know that we will get there. The concept alone is hard for people to understand and hard for companies to adopt. Add to the current complexity of the technology, and I think we’ll see giant leaps forward by 2020, but it will not be commonplace or an ‘invisible’ technology.” –Allison Anderson, manager of learning innovations and technology at Intel Corporation; http://www.linkedin.com/pub/allison-anderson/0/b74/a65
- “The availability of new technologies occurs long before they can be rolled out and implemented on a large scale. I do not see any indication that we are any more ready for a new internet than we are ready to take necessary steps to deal with climate change.” –Benjamin Mordechai Ben-Baruch, senior market intelligence consultant and applied sociologist, consultant for General Motors; http://home.earthlink.net/~bbenbaruch/
- “As a specialist in mapping semantic and social networks mined from the web and developing from these improved optimal communication messages, I envision this first scenario not being dominant in the next 10 years but in approximately 30 years. Research trends tend to have 10-, 20-, and 30-year cycles and then a move upward to begin another series of cycles at a higher level of sophistication. We have already reached the end of the first 30-year cycle given that semantic network analysis of web as we knew it in the ’70s-’80s was when we began semantic network analysis of material available on Computer Bulletin Board Systems (CBBS), Arpanet, Bitnet, etc. We need another 30-year cycle, I think for the first scenario to come to fruition.” – James A. Danowski, professor at the University of Illinois at Chicago, founder of the Communication and Technology Division of the International Communication Association; http://www.uic.edu/depts/comm/facultydanowski.shtml
The semantic web will not really take off until it finds its killer app – something we all find that we need.
- “Tim’s World Wide Web was a very simple and usable idea that relied on very simple and usable new standards (e.g. HTML and HTTP), which were big reason why the web succeeded. The semantic web is a very complex idea, and one that requires a lot of things to go right before it works. Or so it seems. Tim Berners-Lee introduced the Semantic Web Roadmap (http://www.w3.org/DesignIssues/Semantic.html) in September 1998. Since then more than 11 years have passed. Some semantic web technologies have taken root: RDFa, for example, and microformats. But the concept itself has energized a relatively small number of people, and there is no ‘killer’ tech or use yet. That doesn’t mean it won’t happen. Invention is the mother of necessity. The semantic web will take off when somebody invents something we all find we need. Maybe that something will be built out of some combination of code and protocols already laying around – either within the existing semantic web portfolio, or from some parallel effort such as XDI. Or maybe it will come out of the blue. By whatever means, the ideals of the semantic web – a web based on meaning (semantics) rather than syntax (the Web’s current model) – will still drive development. And we’ll be a decade farther along in 2020 than we are in 2010.” –Doc Searls, fellow, Berkman Center for Internet & Society, Harvard University and Harvard Law School, fellow at Center for Information Technology and Society, University of California-Santa Barbara; http://www.linkedin.com/pub/doc-searls/0/0/a54
- “With all due respect to Sir Tim, I think the semantic web has failed to reach critical mass because the benefits aren’t clear enough to warrant a wholesale migration. The evolution of practices on the Web may incorporate SW aspects, but it will be too subtle for users to notice.” –Mark Richmond, technologist for US District Courts, founding board member of the National Online Media Association (1993)
The killer app will come when we can ask the internet questions – and that will make things much more efficient. Conversational search will be the key to opening users’ eyes to the potential for the semantic web.
- “Imagine the ability to access the internet by asking simple questions such as ‘best flight to London’ or ‘best treatment for heart disease for 60-year-olds’ and then have the semantic web give you certifiably correct answers from reliable sources that are timely. This is what will soon be possible using the semantic web and the GGG (Giant Global Graph) of interconnected tuples of global knowledge (Subject, Predicate, Object). We already have the CIA Fact Book, Wikipedia, FOAF and other knowledge sources accessible via the Giant Global Graph. This will certainly get deepened by 2020. Internet users will be able to ask questions without necessarily having to sort through results. Search results themselves will be much more relevant, timely and correctly categorized. Much time will be saved and the overall quality of user experience in terms of trust and utility will be significantly beyond what we have today.” –William Luciw, managing director at Viewpoint West Partners and director at Sezmi Inc., and formerly senior director of products and stand–up philosopher at several other Silicon Valley companies; http://www.linkedin.com/in/williamluciw
- “AI [Artificial Intelligence] watchers predict that natural-language search, which represents a component of semantic search, will replace what some call ‘keywordese’ in five years. Once search evolves from an awkward word hunt – guessing at the key words that might be in the document you’re looking for – to a ‘conversation’ with an AI entity, the next logical step is vocal conversation with your computer. Ask a question and get an answer. No reading necessary. That is the ultimate incarnation of the Semantic web and it will likely exist well before 2020 and will have a significant impact on culture. Barney Pell, whose company Powerset was also working on a conversational-search interface before it was acquired by Microsoft, dismissed the notion that a computerized entity could effectively fill the role of text, but he does acknowledge that breakthroughs of all sorts are possible. ‘The problem with storing raw sounds is that it’s a sequential access medium; you have to listen to it. You can’t do other things in parallel,’ said Pell during our 2007 discussion. ‘But if you have a breakthrough where auditory or visual information could connect to a human brain in a way that bypasses the processes of decoding the written text, where you can go as fast and slow as you want and have all the properties that textual written media supports, then I could believe that text could be replaced.’ The likelihood of that scenario depends on whom you ask, but if technological progress in computation is any indication, we are safe in assuming that an artificial intelligence entity will eventually emerge that allows individuals to process information as quickly or as slowly as reading written language.” –Patrick Tucker, senior editor, The Futurist magazine; http://www.linkedin.com/pub/patrick-tucker/5/574/B86
Creating the semantic web is a difficult thing that will depend on machines that can straighten out the massive confusions and complications that humans create.
- “The truth is that the semantic web is a *hard* problem, and won’t be solved until/unless we have ‘sentient’ or ‘conscious’ Turing-capable computers – which I don’t expect by 2020. On the other hand, a combination of better ontologies and just greater computing capacity will allow more information to be pre-computed and searchable, so ‘search’ and what I call ‘online computer-assisted reasoning’, like Wolfram|Alpha, will be much more powerful. Mostly, however, people won’t really notice, except to complain when a search gives them something other than what they wanted.” –Charlie Martin, correspondent and science and technology editor, Pajamas Media, technical writer, PointSource Communications, correspondent, Edgelings.com; http://www.linkedin.com/in/chasrmartin
- “I may be wrong on this one, but people are busy and lazy, and the applications, like text search, that succeed tend to be ones that require no extra work by those entering data – they are by-products of the work we do for ourselves. We include links in documents because they help us and those using our services, not to help Google better estimate the relevance of the document to a query. It might turn out that a centralized approach, where the mission of organizations like WolframAlpha is to add semantic value, will lead to the ‘Web of data.’” –Larry Press, professor of information systems, California State University, Dominguez Hills
The track record of proponents of artificial intelligence is just not good enough to justify the hope that machines will learn to understand the human meaning of things.
- “In some ways, semantic web has the ideals of Lisp or artificial intelligence in the ’80s – it seems attractive on the surface but the technology still has a long way to go. However, we will continue to evolve towards software that enables easier access to real information, improved software reasoning skills, and a continuation of the ‘do what I mean’ philosophy for human-computer interaction.” –Gerrit Huizenga, solutions architect for the Linux Foundation and IBM; http://www.linkedin.com/in/huizenga
- “Having seen the [very!] limited ‘successes’ of artificial intelligence (with few limited exceptions, e.g. face recognition, etc.) since it was first proposed perhaps half a century ago (or more if you count sci fi proposals), I’m quite cynical about how much can be done along the lines of automatically extracting MEANING from information.” –Jim Warren, founder and chair of the first Computers, Freedom, and Privacy Conference and longtime technology and society activist; http://en.wikipedia.org/wiki/Jim_Warren
- “I think very difficult problems related to artificial intelligence underlie the semantic Web vision. We’ve not made much progress on those problems in decades, and I’m not sure why the next decade would lead to breakthroughs.” –Chris Dede, professor of learning technologies, Harvard Graduate School of Education, emerging technologies expert; http://www.gse.harvard.edu/~dedech/
- “The over-stated promises of AI in the last century demonstrate the difficulty of semantics. Machine-learning techniques have improved dramatically so there will be powerful tools for people to infer semantics, however in 2020 most people will continue to work with unstructured and semi-structured data.” –Gary Marchionini, professor at the School of Information and Library Science at the University of North Carolina at Chapel Hill, US; http://www.ils.unc.edu/~march/
- “Meaning is elusive, depending on context and perspective and a range of human intellectual processes that we still only dimly understand. Despite confident predictions, AI and Expert Systems and other attempts to capture meaning through machine ‘intelligence’ have fallen far short of their hype. The semantic web is only the latest new thing that will disappoint its hopeful champions.” –Mark U. Edwards, senior advisor to the dean, Harvard University Divinity School
- “The semantic web is like artificial intelligence. It’s always just around the corner in theory, and disappointing in practice.” –Seth Finkelstein, anti-censorship activist and programmer, author of the Infothought blog and an EFF Pioneer Award winner; http://sethf.com/infothought/blog/
- “This is the latest incarnation of a long line of futile AI endeavors that have not succeeded and wouldn’t do much of what is hoped for them even if they did reach fruition. This one I would not expect to see by 2030 either.” –Jonathan Grudin, principal researcher in human-computer interaction and computer-supported cooperative work at Microsoft Research; http://research.microsoft.com/en-us/um/people/jgrudin/
- “The semantic web will be here by 2020 but in a modified and evolved form from Berners-Lee vision. As information storage becomes more accessible the ‘semantics’ will be in the applications not in the base web language. With smarter and smarter AI based computing, contextual coding will go away and the base software will do the contextual coding and understanding. Thirty years ago we would have said that a machine’s ability to recognize simple words and signs in varied texts was totally limited with out contextual markers. Today, glorified toys can analyze your yoga moves and correct the form all from an under-$50 US camera linked to gaming device (with how many more times computing power that what it took to get to the moon). I think that we will see a merge of ‘recognition’ technologies and ‘learning’ software to read a text and extrapolate the meaning and links.” –Cameron Lewis, Program Manager, Arizona Department of Health Services
- “The 2020 headlines will proclaim (for the 17th year in a row) that ‘next’ year will be the year that semantic Web takes off (of course, that name will be in disrepute, as will its several replacements such as berner–topia and lee–eden. The false icon of semantic Webbing of 2021 will be known as bernersleesation).” –Steve Sawyer, associate professor, college of information sciences and technology, Penn State University; http://ist.psu.edu/ist/directory/faculty/?EmployeeID=3
Human tendencies, preferences, and habits will determine the extent of the success of the semantic web – and probably thwart full realization of the dream. If people take the time to create sites and databases using information standards, then major progress will be made. Yet plenty of factors could, and likely will, stand in the way.
- “As organizations and news sites put more and more information online, they’re learning the value of organizing and cross-linking information. I think the semantic web is taking off in a small way on site after site: a better breakdown of terms on one medical site, a taxonomy on a Drupal-powered blog, etc. But Berners-Lee had a much grander vision of the semantic web than better information retrieval on individual sites. He’s gunning for content providers and Web designers the world around to pull together and provide easy navigation from one site to another, despite wide differences in their contributors, topics, styles, and viewpoints. This may happen someday, just as artificial intelligence is looking more feasible than it was ten years ago, but the chasm between the present and the future is enormous. To make the big vision work, we’ll all have to use the same (or overlapping) ontologies, with standards for extending and varying the ontologies. We’ll need to disambiguate things like webbed feet from the World Wide Web. I’m sure tools to help us do this will get smarter, but they need to get a whole lot smarter. Even with tools and protocols in place, it will be hard to get billions of web sites to join the project. Here the cloud may be of help. If Google can perform the statistical analysis and create the relevant links, I don’t have to do it on my own site. But I bet results would be much better if I had input.” –Andy Oram, editor and blogger, O’Reilly Media; http://radar.oreilly.com/andyo/
Sure, there will be some resistance, but there are fairly strong incentives to cooperate, too.
- “The semantic web is going to pretty fleshed out by 2020, as most data will be surrounded by rich frames of metadata that help machines make sense of it. It will be stupid to build new databases that don’t expose this metadata and it will be easier and more lucrative to create metadata layers for legacy data.” –Anthony Townsend, director of technology development, Institute for the Future; http://www.iftf.org/user/20
- “By 2020, it’s inevitable that the web will be transformed by intelligent agents and machines talking much more readily and effectively to other machines. Too many people at both ends of the pipe stand to benefit for this not to happen. The web, barely two decades old, has been transformed by the development of technologies like XML and Javascript. Web developers have powerful incentives to keep adding functionality and ease-of-use to browsers. This is partly a matter of the sheer numbers of end-users who have made the Internet part of their daily lives.
- “No less important is the role that has been assumed by the browser as both the primary window on the Internet at large and the interface for many once-distinct functions, like email and FTP. In fact, the web browser has become so central to the online experience that most people I talk to (including communication studies majors) are surprised and confused to learn that the web and the Internet are not co-extensive.
- “What is not a foregone conclusion, however, is the role that Berners-Lee and his allies will play in this development cycle over the next decade. I think it unlikely that the semantic web will grow as a single platform entirely within the control of Berners-Lee and the W3C. There’s too much money to be made and too great a temptation to work around a universal set of standards, as has been demonstrated in the past by companies like Microsoft….
- “But [the semantic web] faces a number of major obstacles. First, competitive issues. Not everyone subscribes to the vision expounded by Berners-Lee. There’s probably a lot of money to be made here, a compelling reason for some developers to create solutions outside the semantic web framework. Second, technical issues. Natural language is rife with ambiguity, a nasty problem that has plagued machine-assisted translation for decades. It’s hard to imagine the semantic web as an end-game, with humanoid agents able to operate free of human intervention. Third, social issues. The very success of such a radical user-interface paradigm will pose threats to end-user control and privacy. The more the semantic web succeeds, the more we should be concerned about what we’re forfeiting to our agents and those who create them…. In other words, the semantic web should not be seen as entirely benign. Once out of the lab, it will have to contend with the many frailties, and occasional bad faith, of the creatures it’s intended to help.” –David Ellis, director of communication studies at York University, Toronto, and author of the first Canadian book on the roots of the Internet; http://ca.linkedin.com/in/drdavidellis
There will be an upstairs-downstairs quality to adoption and use. Elite and specialized users will be able to take advantage of the semantic web in ways that everyday internet users likely will not. Business applications will have more stakeholders than consumer or social apps. Particular activities will be the norm, rather than activities that appear similar throughout the web.
- “Within restricted communities or small families of websites, ontologies are possible without strangling the development of a community, but across the entire web? No way. Never. ” –Chris DiBona, open source and public sector engineering manager at Google; http://sites.google.com/a/dibona.com/dibona-wiki/Home/Biographies-and-Photos
- “The semantic web is just now being applied to specialized fields like medicine, music, geography… Google opens a big front door to the electronic library, but SWs [semantic webs] are the card catalogs of the specialized stacks.” –Don McLagan, board of directors member for the Massachusetts Innovation & Technology Exchange, consultant to digital entrepreneurs, retired CEO of Compete Inc.; http://www.linkedin.com/pub/don-mclagan/0/26/237
- “There are far too many challenges for the semantic web to make a significant difference in the average user’s experience – BUT there will be leaders that make good use of the tools that can help to create sites where Semantic programming and tools can be implemented. The internet is vast, and I think that predictability/vagueness are major issues to overcome in this area.” –Stephan Adelson, president of Adelson Consulting Services and founder of Internet Interventions, a company that promotes health and patient support; http://www.linkedin.com/in/sadelson
- “I do think the semantic web will have taken hold, but that it will remain a specialist and complex section of web development work. The average user may well not perceive much impact on their daily lives, as the impact will be broad but shallow, affecting millions of people in a very small way, adding that little extra benefit in terms of user experience to their daily web work. I do think however that there will be specific business benefits that have yet to be acknowledged, specifically in internal (i.e. private) business intelligence. The ability of the semantic web to not only reveal complex data about a businesses internal machinations, but also to then visualise and combine this data into meaningful graphs that can be used for strategic decisions may well be the killer app that linked data is looking for.” –Rich Osborne, web manager and web innovation officer, University of Exeter; http://education.exeter.ac.uk/staff_details.php?user=rmosborn
- “The semantic web might prove useful in certain tightly controlled domains, but true artificial intelligence remains elusive.” –Dean Thrasher, founder, Infovark; http://www.linkedin.com/in/deanthrasher
- “I interpret the semantic web as optimized design principles, taking root today. And some principles, in my opinion, do not jive well with average human behavior – either from the perspective of developers or users. It will take a long time to penetrate web development norms, and those principles that do make it through probably will not ‘reach’ the average user until some time past 2020. It will be under-recognized by the average person, fully understood only by IT and web developer communities.” –Paul DiPerna, research director and editor at the Foundation for Educational Choice; http://www.edchoice.org/about/ShowBiography.do?id=30&staffType=management
- “Much depends on the definition. But a lift from the mechanical techniques acting on physical expressions and limited grammars employed by Google, etc., into a semantic level of content analysis will only take place within very limited frameworks, and even so limited, they will be extremely sensitive to the semantic variations and rule changes developing over time as it is clearly manifested in ordinary language as well as in the scholarly and scientific vocabularies.”—Niels Ole Finnemann, professor, director at the Center for Internet Research, Department for Information and Media Studies, Aarhus University, Denmark
- “The semantic web could give us the power of Asimov’s robots. If so, world productivity goes up, and economic prosperity improves – or does it? Whether good or bad depends a lot on access, not just electronic, but intellectual. Will everyone have the education to best use such a world, or does the computer just get smarter so that humans can get dumber?” –Ed Lyell, professor of business and economics, Adams State College, designer and consultant for using computers and telecommunications to improve school effectiveness through the creation of 21st century learning communities; http://www.edlyell.com/About.html
- “There is a clear benefit to achieving the semantic web but this may not be apparent to the average user, which in turn suggests that there may be insufficient financial incentive (i.e. return) to investors to bring it about. Business users might benefit, but systems administrators may prefer to stick with user-allocated metadata as a more easily understood and trusted method of document tagging and description. Document and records management systems need to evolve considerably not just to incorporate the semantic web but to offer clear advantages to corporate buyers needing to comply with disclosure legislation (Freedom of Information, Sarbanes-Oxley, etc).” –Peter Griffiths, independent information specialist and consultant and former president of the UK Chartered Institute of Library and Information Professionals; http://uk.linkedin.com/in/peterdgriffiths
The very essnce of the idea of the semantic web continues to evolve, as does every aspect of the Internet; it is difficult to predict what will happen because the aspirations of its proponents are shifting to take account of new realities and current limitations.
- “The semantic web is a liquid concept that has changed as technology – and socioeconomic – interests have evolved along time. In a broad sense, the semantic web is about machines understanding humans – their behaviour, their actions, their knowledge outcomes – without these having to tell or command them. In this broad sense, the semantic web is likely to leap forward in the coming years. Augmented reality will begin to seriously bridge the offline and the online worlds or, better said, to bridge analogue and digital worlds. This bridge will accelerate the already vertiginous path towards pouring immense amounts of data in digital format, which will definitely help search engines and all computing tasks in general in performing semantic activities. Of course, the evolution of hardware will also contribute in this, and we are likely to see an understandable ’step back’ in software design: it might become worth it to replace clever algorithms with brute force ones, where quantitative approaches (more data with more computing power) might be better than qualitative ones (related with efficiency based on metadata attached to data). In any case, despite the state of evolution of the semantic web, a point of no return will by then have been reached in the way we understand the dichotomy of analogue and digital, and having entered a new paradigm where offline vs. online will no more make much sense.” – Ismael Peña-López, lecturer, School of Law and Political Science, Open University of Catalonia, researcher, Internet Interdisciplinary Institute; http://es.linkedin.com/in/ictlogist
- “By 2020, the promoters of the semantic web will change their definitions and declare victory.” – Alex Halavais, vice president of the Association of Internet Researchers; professor and social informatics researcher, Quinnipiac University; explores the ways in which social computing influences society, author of “Search Engine Society”; http://alex.halavais.net/bio
- “The ‘semantic web’ is a direction for technology development, not a ‘thing’ that can be ‘achieved,’ and whether average internet users notice not a particularly useful question. (For example, average internet users don’t notice much of a difference from ‘XML’ either, even though XML has had significant positive impact in industry.) – Larry Masinter, principal scientist at Adobe Systems, TAG member at W3C, formerly Internet architecture director at AT&T; http://www.linkedin.com/in/masinter
- “Already the semantic web folks have backed off on their stated expectations and are more interested in data portability and interoperability. Frankly this is not only a realistic move but a smart one. The best place for semantics is in data which structure and metadata and description are essential.” –Paul Jones, founder and director of ibibilo.org, University of North Carolina-Chapel Hill; http://www.ibiblio.org/pjones/
There are some applications and activities online that show the promise of the semantic web, among them: TripIt, Xobni, TrueKnowledge, Wolfram|Alpha, Open Calais, Hakia.
- “Although the semantic web may not play out precisely as envisioned, it is already having an effect and will continue to do so. Semantic applications already manage email contacts (Xobni), travel plans (TripIt), and searching and finding (TrueKnowledge, Wolfram|Alpha, and many others). The power of the semantic web is that it is using information that is already embedded in our systems to make and display connections that would take much longer to surface one by one. For instance, TripIt uses semantic approaches to interpret travel information; by forwarding a collection of confirmation emails from a variety of sources to a single automated address, I end up with an easy-to-read, integrated itinerary of all my trips, a task that used to require me to find, print out, staple, and keep track of numerous pieces of information. The semantic web makes this possible, and as more semantic applications are developed and released, it will become easier to keep track of and use the multitude of information that each of us deals with on a daily basis. That said, I don’t think it will be obvious to most people that the semantic web is what makes this possible – the technology will be transparent.” –Rachel S. Smith, vice president, NMC Services, New Media Consortium; http://www.linkedin.com/in/ninmah
- “Structured metadata is hard. It would be possible to do what Sir Tim envisions today, but it requires a great deal of effort by content creators. It’s unlikely to happen for most content unless tools are built to make it automatic and transparent. Systems like OpenCalais are promising, but many generations away from being truly effective. This isn’t something I expect to see by 2020.” –Ethan Zuckerman, research fellow, Berkman Center for Internet and Society at Harvard Law School, co-founder of Global Voices; http://ethanzuckerman.com
- “I believe that by 2020 there will be mechanisms for interoperable computer programs that will allow easy and invisible sharing of data across applications that will make the goals of a semantic web attainable. This will make it easier for all internet users to seamlessly operate and combine document, data, calendar, social media, multimedia, and other programs.” –Gary Kreps, chair of department of communications, George Mason University
- “The semantic web is here. Pay close attention to organizations like Hakia, for example. We’ll see change well before 2020.” –Joshua Fouts, leader of Dancing Ink, fostering the emergence of a new global culture through virtual worlds, a digital diplomacy expert, senior fellow at Center for the Study of the Presidency and Congress, web activist and founding editor of Online Journalism Review; http://www.linkedin.com/in/joshuafouts
Some point out that despite human differences, the promise of the semantic web gives people significant incentives to cooperate in building it. Some say there are no incentives.
- “Once people start understanding the need of semantic web, more and more websites will be based on semantic concepts, which will lead Google to reflect the outside webworld in semantic format.” –Rudi Vansnick, president, Internet Society of Belgium
- “For this question the answer will lie somewhere in between the choices provided. It is clear that the volume of information on the Internet in 2010 is overwhelming and those who can find ways of extracting intelligence from this in a scalable way will have an advantage. In the next 10 years we will be thousands of startups who will invent pieces of the puzzle in making sense of the depth and breath of content. The semantic web will be a piece of this, but by no means the single answer.” –Tom Golway, global technology director at Thomson Reuters and former CTO at ReadyForTheNet; http://www.linkedin.com/in/readyforthenet
- “There’s currently little or no incentive to create the semantic web, from the perspective of the people who actually have to do the work. As such, it will fail to thrive.” –Cameron Price, CTO for Mint Digital
Some made suggestions about what a semantic web should aspire to be.
- “We do not have a true hypertext system and the standards have not addressed some of the key shortcomings. We need two-way linkages so a person can go in either direction for such links. We need collaborative features where a user can choose to authorize the return link being placed in their webpage. We need people to be able to create multidimensional linkages among items and produce them new products of creative writing or new nonlinear documents. We need the partial opening of copyright restrictions to allow people to take fragments from anywhere to create these new types of information collections. Some of this is available through some sharing systems but they are often divided by the type of information like pictures, video, etc. There is still too much fragmentation and currently social networks try to force a person to do everything through a given system and not allow a user to direct things to any integration capability with all their information behavior.” –Murray Turoff, professor of computer and information sciences, New Jersey Institute of Technology; http://www.linkedin.com/pub/murray-turoff/6/697/163
- “Common languages, filing systems, and methods (scientific method) define the intellectual worlds in which we live. This is merely an extension. However, on the downside, they also may circumscribe thought as order replaces chaos. The trick is not to lose the chaos of the past decades with non-flexible associations.” –Tom Wolzien, chairman of Wolzien LLC Media & Communications Strategy and formerly senior analyst with Sanford C. Bernstein & Co.
- “The semantic web is the end game of the internet we use today which is but a stepping stone to something more useful. It completes the usefulness of having developed a multitude of disparate information sources that can be linked programmatically to provide collective intelligence.” –Jeff Walpole, CEO, Phase2 Technology, a web application development firm
- “The Internet was created to connect computers (and then documents, etc) in the case of a meltdown on one node; it was not created for average users. We don’t really care about sites or remembering yet another place, in fact we would much prefer content to come to us as part of the ‘Destination-Free Web.’ As our interests and needs shifts we would prefer something to self-organize content that matches our mood. In a simple case – search should fragment into Information Search, Social Search, and Commercial Search.” –Anthony Power, vice president of interactive and analytic solutions at Studeo and author of “What’s Still Missing from Web 2.0”; http://www.studeo.com/content/anthony-power
- “Taxonomy is destiny on the web. By 2020 we will all better understand tagging and searching and will leverage the semantic web to our advantage. The continuous gaming of the semantic system will continue but as publishers and merchants seek more advantage, the public will benefit from incremental specificity in search and in quick access to the information sought.” –Daniel Flamberg, blogger at iMedia Connections and senior vice president of interactive marketing at Juice Pharma Advertising; http://www.plaxo.com/directory/profile/90196792005/fbcfdefa/Daniel/Flamberg
Additional expert interviews and talks from FutureWeb 2010
Below are links to video and summaries of several sessions at FutureWeb 2010, in which experts from this survey discuss the future of the internet:
- Lee Rainie , director of the Pew Research Center’s Internet and American Life Project, delivered a keynote on the Future of the Web and answered audience questions: http://www.elon.edu/e-web/predictions/futureweb2010/lee_rainie_keynote.xhtml
Lee’s interviews with:
- Sir Tim Berners-Lee, inventor of the World Wide Web, and Danny Weitzner, formerly W3C Technology & Society Policy director, now the associate administrator for policy at the United States National Telecommunications and Information Administration
- Vint Cerf , Internet Protocol co-innovator and Google vice president
- danah boyd of Microsoft and Harvard University’s Berkman Center, addressing the opportunities and challenges that lie ahead
- Doc Searls , a co-author of “The Cluetrain Manifesto,” senior editor for Linux Journal, and fellow at the Berkman Center at Harvard and at the Center for Information Technology & Society at the University of California at Santa Barbara, on the influence of the Web (includes a public question-and-answer session)
- Bob Young , CEO of Lulu.com, on the future of publishing
- Marc Rotenberg , executive director of the Electronic Privacy Information Center, on the future of the Web

