As Americans increasingly use social media, researchers naturally are interested in how the data from it can be used to better understand how users share and discuss information on these new platforms. The mass of tweets, ranging from political commentary to overall “sentiment” about companies, products or services, has many marketing firms and academics clamoring for insights into Twitter’s collective stream of consciousness.
But how accurate is Twitter as a measure of public sentiment and how can it be used? At Pew Research Center, we’ve been specifically interested in experimenting with Twitter’s role in the news since 2008. So when we launched a yearlong project examining local news in three cities last year, we tested several approaches using Twitter data to understand how it serves as a source of news and enables local residents to become participants in it.
Our verdict? While Twitter analysis is still at an experimental stage and Twitter data has limitations, it can be a valuable new tool to understand the media environment. More specifically, we found it valuable to understand how news organizations use Twitter. However, local news is just one small topic of many discussed on the platform. What we found lacking was trying to glean any data about Twitter users by location.
Here’s a rundown of what worked and what didn’t in using Twitter for research.
What we did:
We wanted to understand what role Twitter plays as a source for news for local residents of three case study cities: Denver, Macon, Ga., and Sioux City, Iowa. This included tracking traditional news organizations on Twitter, such as newspapers, television and radio stations, as well as newsmakers themselves, such as politicians, community leaders and government officials. To do this, we mostly used the service Gnip to access the Twitter “firehose,” which refers to access to all of the tweets and metadata on Twitter.
Rather than take Twitter users as a proxy for their larger community, we simply treated Twitter users in each city as a community in and of themselves. We did a comprehensive audit of news providers in each city and found that most of them had Twitter accounts. Even if a relatively small portion of the population is on Twitter, the news organizations’ use of Twitter could serve as a useful tool to understand how local information spreads through a community.
Second, we wanted to know whether residents of each city were using Twitter to comment on, discuss and even participate in news events. We experimented with several different methods before settling on a combination of approaches that would best answer the questions at hand.
In doing this analysis, we kept in mind general limitations of using Twitter to talk about what the public thinks, does or values. Unlike the representative phone surveys that we conduct, those on Twitter are not representative of the population as a whole. Overall, our surveys show that roughly 23% of online adults are on Twitter, and that those who get their news from the site are younger, more educated and more likely to own a smartphone than the general population.
How we did the analysis:
The first task in creating a sample of tweets for each city was to find a reliable way of generating geographic boundaries for the tweets from the target cities.
That proved challenging, as looking at geotags or self-identified locations of Twitter users – the seemingly obvious solutions – were not workable answers. On Twitter, users must opt in to have their tweets automatically tagged with a location, and very few do; most estimates are that only around 2% of tweets have geotags. This proved true in this study as well: In the three cities studied across a one-week field period, there were almost no geotagged tweets at all.
We then looked at Twitter users’ self-identified location based on their Twitter profile. We examined a sample of tweets in each city and found that the majority of users either did not fill out this information or filled it out with information that was not useful. For example, “the moon” and “outer space” were extremely popular locations. Even in cases where there was a usable location, there was no straightforward way to verify that users actually lived where they said they did.
Instead, we turned to a technique that’s called “snowball” or “chain” sampling.
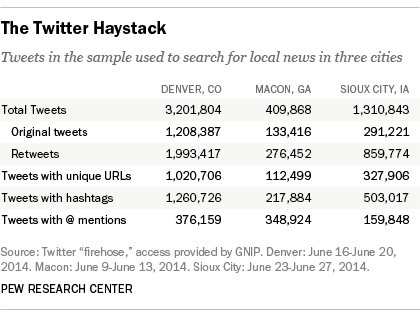 Since we had already collected the Twitter handles of news providers in each city, we pulled from this initial list of all tweets any Twitter handle, or user, who had @ mentioned or retweeted a news provider’s handle during the time period studied. We did this because mentioning or retweeting news indicates that the Twitter user is engaged with it, either as a news consumer or someone who wants to spread the news. While we were aware we could not guarantee that all of the new handles would be directly connected to each community, it gave us a starting point to further refine the sample.
Since we had already collected the Twitter handles of news providers in each city, we pulled from this initial list of all tweets any Twitter handle, or user, who had @ mentioned or retweeted a news provider’s handle during the time period studied. We did this because mentioning or retweeting news indicates that the Twitter user is engaged with it, either as a news consumer or someone who wants to spread the news. While we were aware we could not guarantee that all of the new handles would be directly connected to each community, it gave us a starting point to further refine the sample.
This step increased the total number of Twitter users in the sample from several hundred to more than 30,000. Finally, researchers pulled all the tweets from each handle that had been identified either as a news provider or a news consumer during the time period for each city. That resulted in more than 4.7 million tweets.
We then further narrowed that sample of 4.7 million in order to find tweets relevant to the focus of the study about local news on Twitter – an important step because we found that the overwhelming majority of Twitter content during the week studied was not local in nature.
We tried refining the sample by studying URLs being shared on Twitter in each city and by looking at keywords. Roughly 40% of the tweets included a URL, or link to another webpage. Researchers created a program that would go to each webpage and scan it for keywords that would associate the page with each city. Using Macon as a test case, we created a list of keywords based on Macon’s metropolitan statistical area (MSA). The 26 keywords included all of the county and town names included in Macon’s MSA. In practice, these keywords did not work. Even these keywords, which were specific to the geographic area, were too general to be useful.
Even if this method had worked, there was still the problem of the 60% of tweets that did not contain a URL. The failure of the keyword strategy and the issue of the additional 60% of tweets led us to the final method we used for the study.
What worked:
In the end, the solution was a social media analytics tool called Crimson Hexagon, which analyzed our entire sample of tweets for the most common keywords and hashtags. Crimson Hexagon is software that can be used to analyze large volumes of tweets and extract various pieces of information. In this case, we used the tool to remove tweets irrelevant to our research. These included tweets sent from countries outside the U.S. and tweets that were not in English.
After removing those, we used Crimson Hexagon to find the most frequently used words and phrases in the content of the tweets. This revealed to us that local news content on Twitter is far outpaced by national news and other content. Keywords about local news were virtually impossible to find with any frequency.
Despite the usefulness of tools like Crimson Hexagon, in the end we found the most success with a far-less technical tool: humans. We simply read tweets – tens of thousands of them – to find local news. This process also allowed us to better understand where local news did appear and how it was being shared.
Combined with a content analysis of local news sources, our findings showed that even what little local news was being shared on Twitter was often different from what was being covered by news outlets in each city. For example, in Macon, the most shared story on Twitter by far was about a local band that had made it into a contest on VH1. This story was hardly covered at all in the mainstream press during the week studied.
There are more technical tools available for mapping large trends on Twitter, such as monitoring a global hashtag. But for our purposes, examining news in smaller communities, the Twitter data was so sparse that it was not as useful as we had hoped.
