Survey methodology
Most of the analysis in this report is based on telephone interviews conducted Feb. 29 to May 8, 2016, among a national sample of 3,769 adults, 18 years of age or older, living in all 50 U.S. states and the District of Columbia (977 respondents were interviewed on a landline telephone, and 2,792 were interviewed on a cellphone, including 1,676 who had no landline telephone). The survey was conducted by interviewers at Princeton Data Source under the direction of Princeton Survey Research Associates International (PSRAI). Interviews were conducted in English and Spanish. For detailed information about our survey methodology, see https://legacy.pewresearch.org/methodology/u-s-survey-research/
Four separate samples were used for data collection to obtain a representative sample that included an oversample of black and Hispanic respondents. The first sample was a disproportionately stratified random-digit dialing (RDD) landline sample drawn using standard list-assisted methods. A total of 822 interviews were completed using this RDD landline sample. The second sample was a disproportionally stratified RDD cell sample to oversample blacks and Hispanics. A total of 2,440 interviews were completed using this RDD cell sample. Respondents in the landline sample were selected by randomly asking for the youngest adult male or female who is now at home. Interviews in the cell sample were conducted with the person who answered the phone, if that person was an adult 18 years of age or older.
The landline and cell callback samples were drawn from recent Pew Research Center surveys conducted by PSRAI and included people who identified themselves as black at the time of the initial interview. All surveys used to produce the callback samples employed RDD sampling methodologies.
The weighting was accomplished in multiple stages to account for the disproportionately stratified samples, the overlapping landline and cell sample frames and household composition, the oversampling of blacks through callback interviews, and differential non-response associated with sample demographics.
The first stage of weighting corrected for different probabilities of selection associated with the number of adults in each household and each respondent’s telephone usage patterns. 20 This weighting also adjusts for the overlapping landline and cell sample frames and the relative sizes of each frame and each sample. Since we employed a disproportionately stratified sample design, the first-stage weight was computed separately for each stratum in each sample frame. The callback sample segments were assigned a first-stage weight equal to their first-stage weight from their original interview. After the first-stage weighting an adjustment was made to account for the callback oversamples, landline and cell, of blacks.
The next step in weighting was demographic raking. The data was first divided into three groups – black, Hispanic and white/other. Each group was raked separately to population parameters for sex by age, sex by education, age by education and census region. The white/other group was also raked on a two-category race variable – white vs. not white. The Hispanic group was also raked on nativity – U.S. born vs. foreign born. The combined dataset was raked to parameters for race/ethnicity, population density and household telephone usage. The telephone usage parameter was derived from an analysis of the most recently available National Health Interview Survey data. 21 The population density parameter was derived from Census 2010 data at the county level. All other weighting parameters were derived from an analysis of the 2014 American Community Survey 1-year PUMS file.
The margins of error reported and statistical tests of significance are adjusted to account for the survey’s design effect, a measure of how much efficiency is lost from the weighting procedures.
The following table shows the unweighted sample sizes and the error attributable to sampling that would be expected at the 95% level of confidence for different groups in the survey:
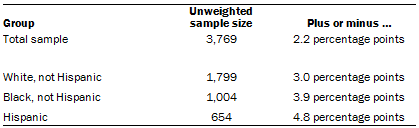
Sample sizes and sampling errors for other subgroups are available upon request.
In addition to sampling error, one should bear in mind that question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
Pew Research Center undertakes all polling activity, including calls to mobile telephone numbers, in compliance with the Telephone Consumer Protection Act and other applicable laws.
Analyses of secondary data
In Chapter 1, the analyses of education, household income, homeownership, poverty and unemployment are all based upon the Current Population Survey, Annual Social and Economic Supplement (ASEC), which is conducted in March of every year. The specific files used in this report are from March 1962 to March 2015. Conducted jointly by the U.S. Census Bureau and the Bureau of Labor Statistics, the CPS is a monthly survey of approximately 55,000 households and is the source of the nation’s official statistics on unemployment. The ASEC survey in March typically features a larger sample size.
The ASEC surveys collect data on the income of a household in the preceding calendar year. Thus, the 1968 to 2015 files used to analyze income and poverty in this report refer to 1967 to 2014. Data regarding education, homeownership and unemployment are based upon the time of the survey.
The 2015 ASEC utilized a redesigned set of income questions, so the household income figures reported for calendar year 2014 may not be fully comparable to earlier years. Further details on this redesign and its impacts can be found here. Methodological revisions in the CPS may also have an impact on the trends in household income. In particular, the 1993 revisions have an impact on the comparability of income data before and after that date. 22
Household income and household wealth figures were converted to 2014 dollars using the research series of the consumer price index (CPI-U-RS).
The income data are also adjusted for the number of people in a household. That is done because a four-person household with an income of, say, $50,000 faces a tighter budget constraint than a two-person household with the same income. In addition to comparisons across households at a given point in time, this adjustment is useful for measuring changes in the income of households over time. That is because average household size in the United States decreased from 3.2 persons in 1970 to 2.5 persons in 2015, a drop of 21%. Ignoring this demographic change would mean ignoring a commensurate loosening of the household budget constraint. Further detail on the manner in which the Pew Research Center adjusts household income for the size of the household can be found here. The adjusted household income figures are presented for a household size of 3.0.
Data regarding children’s living arrangements, as well as the marital status of adults, are derived from the decennial census (for 1960, 1970, 1980, 1990 and 2000) and the American Community Survey for all other years. Both produce datasets that are nationally representative.
The decennial census, American Community Survey, and CPS microdata used in this report are all derived from the Integrated Public Use Microdata Series (IPUMS) provided by the University of Minnesota. The IPUMS assigns uniform codes, to the extent possible, to data collected over the years. More information about the IPUMS, including variable definition and sampling error, is available at https://www.ipums.org/
The poverty rate figures are derived from the CPS but were not tabulated from microdata. Historical poverty figures are published by the U.S. Census Bureau.
Wealth analyses are derived from the Survey of Consumer Finances (SCF). The SCF is sponsored by the Board of Governors of the Federal Reserve System in cooperation with the U.S. Department of the Treasury and has been collected every three years since its inception in 1983. The interviews are conducted roughly between May and December. The most recent SCF available is for 2013. The tabulations presented are based on the public use version of the SCF available on the Federal Reserve’s website: http://www.federalreserve.gov/econresdata/scf/scfindex.htm. The SCF sample typically consists of approximately 4,500 households
The definition of a “household” in the SCF differs from that used in Census Bureau studies. The sampling unit in the SCF is the “primary economic unit” (PEU), not the household. As stated by the Federal Reserve Board, “the PEU consists of an economically dominant single individual or couple (married or living as partners) in a household and all other individuals in the household who are financially interdependent with that individual or couple.” Federal Reserve Board publications refer to the PEU as a “family,” but readers may infer that this necessitates the presence of two related persons, though a PEU can consist of a person living alone. In this document, a PEU is referred to as a “household.”
Data regarding non-marital births are obtained from the National Center for Health Statistics (NCHS). These vital statistics data reflect information extracted from completed birth certificates for live births, which include the mother’s characteristics at the time of the birth. The tabulations are based upon births occurring in the 50 states and the District of Columbia to people living in the United States in a given calendar year.
Pew Research Center is a nonprofit, tax-exempt 501(c)(3) organization and a subsidiary of The Pew Charitable Trusts, its primary funder.

 Interactive How blacks and whites view the state of race in America
Interactive How blacks and whites view the state of race in America