
The challenges of using machine learning to identify gender in images
In recent years, computer-driven image recognition systems that automatically recognize and classify human subjects have become increasingly widespread. These algorithmic systems are applied in many settings – from helping social media sites tell whether a user is a cat owner or dog owner to identifying individual people in crowded public spaces. A form of machine intelligence called deep learning is the basis of these image recognition systems, as well as many other artificial intelligence efforts.
This essay on the lessons we learned about deep learning systems and gender recognition is one part of a three-part examination of issues relating to machine vision technology. See also:
Interactive: How does a computer “see” gender? By systematically covering or “occluding” parts of photos of individual people’s faces and then feeding those images into a computer model we created, we could see which elements of a face are most important to helping the model classify men and women. We created an interactive feature where you can recreate that analysis and see which changes cause our deep learning algorithm to change its guess about the gender of the person in the image.
Public opinion survey on facial recognition. Facial recognition systems that can determine the identity of individuals based on a photo or video are one of the more controversial applications of machine vision (the models we used for this project can classify gender but are not able to identify individual people). The Center recently conducted a survey of U.S. adults examining public opinion toward facial recognition technology and its use by advertisers, law enforcement and others. See our report on this survey here.
Deep learning systems are often “trained” to perform these tasks by being presented with many examples of pictures, objects or scenarios that humans have already labeled “correct” or “incorrect.” By looking at enough examples, these systems can eventually learn how to identify unlabeled objects or scenarios they have never encountered before. These labeled examples that help the system learn are called “training data,” and they play a major role in determining the overall accuracy of these systems.
These systems offer the potential to perform complex tasks at a speed and scale far beyond the capacity of humans. But unlike people, deep learning systems typically cannot provide explanations or rationales for their individual choices. And unlike traditional computer programs, which follow a highly prescribed set of steps to reach their outcomes, these systems are sometimes so complex that even the data scientists who designed them do not fully understand how they come to their decisions.
As a result, these systems can fail in ways that seem difficult to understand and hard to predict – such as showing higher rates of error on the faces of people with darker skin relative to those with lighter skin, or classifying prominent members of Congress as criminals. And the use of these systems in areas such as health care, financial services and criminal justice has sparked fears that they may end up amplifying existing cultural and social biases under the guise of algorithmic neutrality.
Pew Research Center recently applied deep learning techniques in a series of reports that examined gender representation in Google image search results and images from news posts on Facebook. Because it was not feasible for human researchers to sort through and classify the thousands of images produced by these online systems, we created our own tool to automatically detect and categorize the gender of the people in the images we found.
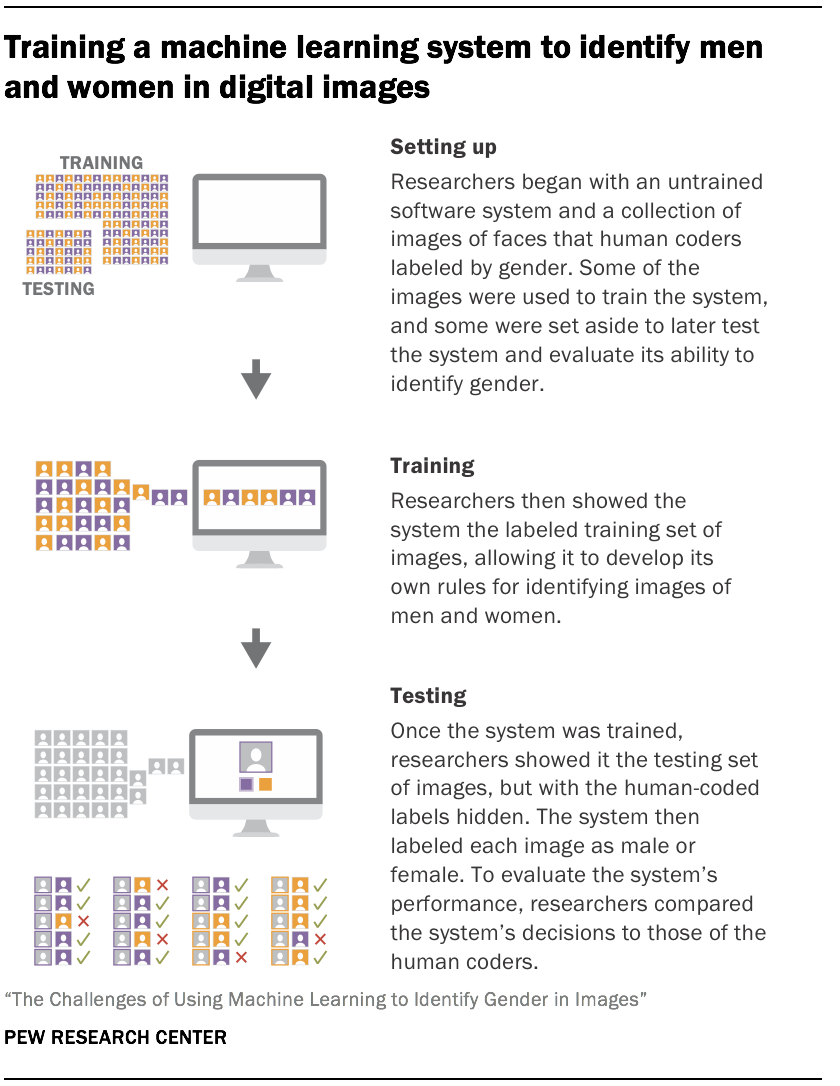 In the process of building a deep learning system to recognize gender across a diverse range of human faces in images, we learned firsthand the difficulties of understanding how these systems function; the challenges of adjusting them to perform more accurately; and the critical role of the data used to train them in making them perform more (or less) effectively. We trained and tested more than 2,000 unique models based on a common deep learning architecture, and in the process uncovered a great deal of variation in these models’ ability to accurately identify gender in diverse sets of images.
In the process of building a deep learning system to recognize gender across a diverse range of human faces in images, we learned firsthand the difficulties of understanding how these systems function; the challenges of adjusting them to perform more accurately; and the critical role of the data used to train them in making them perform more (or less) effectively. We trained and tested more than 2,000 unique models based on a common deep learning architecture, and in the process uncovered a great deal of variation in these models’ ability to accurately identify gender in diverse sets of images.
One common limitation of many gender classification systems (including the one we used to conduct our own research) is that they cannot account for individuals who do not identify as either a woman or a man, and they have no concept of gender identity as separate from physical appearance. But even beyond these known limitations, we learned that the training data used to train these models matters greatly. The models that we trained using more diverse sets of images (which includes their demographic composition as well as the quality and types of images used in each set) were better at identifying gender in a similarly diverse group of photos than models that were trained on more limited data.
We also noticed variation in the performance of these models that was sometimes surprising and difficult to explain. For instance, even though the models that were trained using greater diversity were the most accurate, some models that were trained on less diverse images were more accurate than others. Similarly, some of these models were better at identifying men than women, while others overperformed on women rather than men.
How we built machine learning models using diverse images
Data collections used in this analysis
Machine learning models typically start as blank slates that haven’t been shown any data and are incapable of performing classifications or any other tasks. The models we discuss in this essay were built with a technique called “transfer learning,” which gives them some basic information about how to identify common objects, but not necessarily information specifically relevant for estimating gender. Regardless of the specific type of machine learning being used, data scientists usually begin constructing a model by selecting a dataset that depicts many instances of the task or classification being performed correctly. After seeing enough examples of this so-called training data, the model eventually identifies systematic patterns and develops its own approach to distinguishing the “correct” answers from the “incorrect” ones. It can then use that approach to perform the task it has been trained to do on data it has never seen before.
However, examples that are biased or don’t accurately represent the broader group of individuals that might be encountered can teach the system unexpected and meaningless patterns, causing it to develop an approach that doesn’t work well on new data. For example, a model trained on images in which every man is wearing glasses might be convinced that wearing glasses is a strong signal that someone is a man. While this example might seem obvious, it can be difficult to know in advance if training data consists of poor examples for the task, or if it is unrepresentative.
Since we wanted our analysis to distinguish between men and women in images, our training data consisted of equal-sized sets of images of men and women in which each image was labeled as a man or a woman. We wanted to see how the choice of training data impacted the overall accuracy of our models, so we searched online for different collections of images of human faces. We eventually gathered seven collections of images that we used for training our models. Each collection consisted of labeled images of individuals, but each one had its own unique mix of age ranges, races, and nationalities, as well as a mix of image characteristics such as image quality and positioning of the individual.
Using these collections as a starting point, we then created eight different training datasets for our deep learning models. Seven of the training datasets consisted of images drawn from only one of the original collections (a simulation of different types of less diverse training data) while one of the training datasets consisted of images drawn from a mix of all seven collections (a simulation of more diverse training data). Crucially, all eight datasets used for training were the same size and contained an equal number of men and women.
How these models performed at identifying gender in diverse sets of images
After each model was trained from one of the eight training datasets we had created for this project, we tested it. To compare the performance of the different models, we created a unique dataset composed of images taken from all seven of the original data collections – but that were never used to train any of the individual models. This type of dataset is known as “testing data” and is used to evaluate and compare the performance of the different models. The testing data for this project contained an equal number of images from each of the seven data collections, as well as an equal number of images identified as depicting women and men within each individual collection.
When we ran our trained models on the testing data, we found some of the models performed more accurately than others. Most notably, the model that had been trained on images taken from all seven of the individual collections (that is, the model trained on the most diverse set of training data) had the best performance. It accurately identified the correct gender for 87% of the training data images, while the models trained using only one of the individual data collections achieved accuracies of between 74% and 82%.
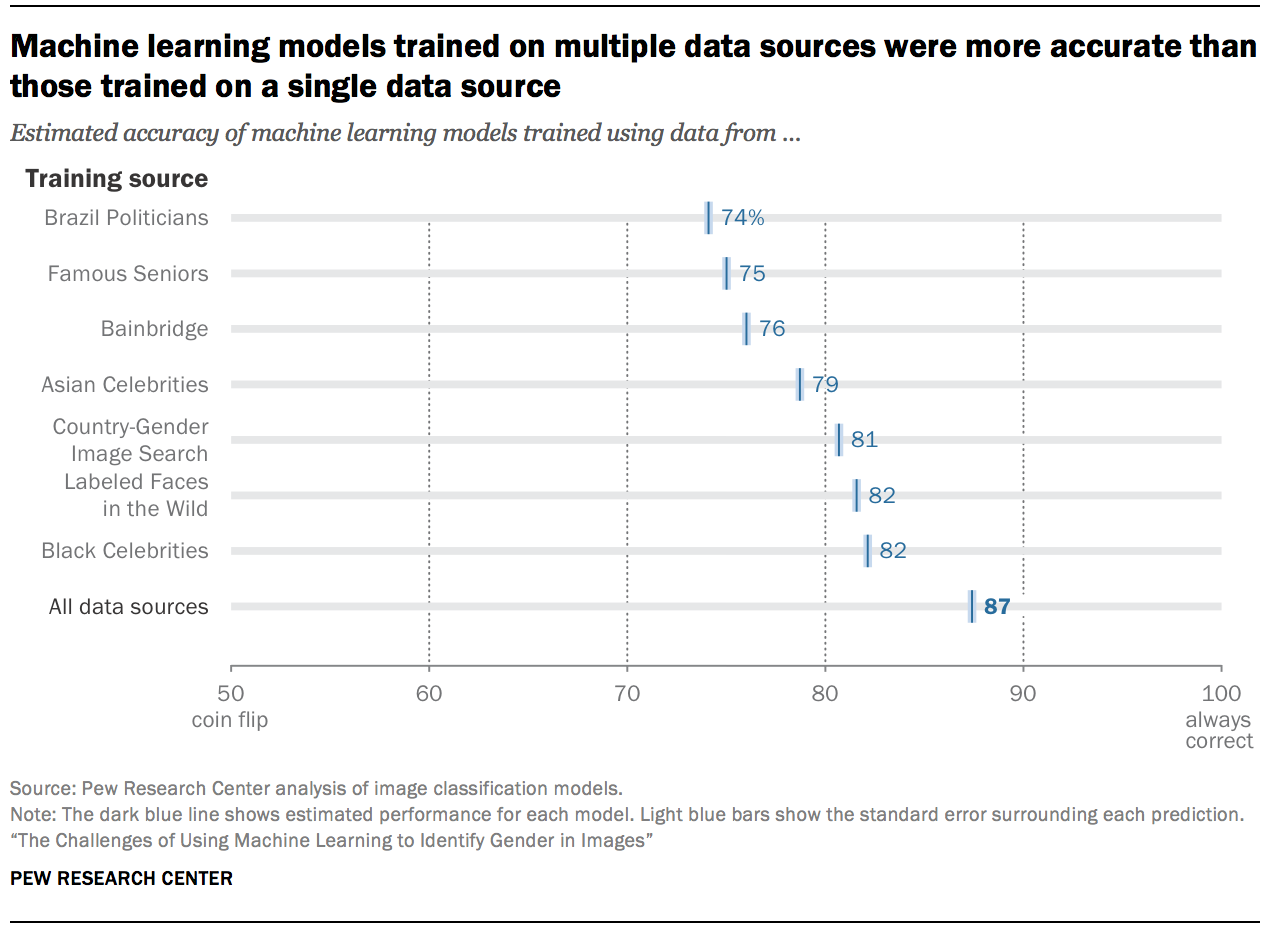
In other words, the model that was trained on a diverse set of sources performed significantly better than those trained on individual sources, even though every model saw the same number of total images and the same ratio of men to women. This is not altogether surprising, since the diverse training data and the testing data both contained a mix of the seven data collections. This highlights a central challenge facing those who build or use these types of models: Models built using training data that looks different from real-world data, and all the real-world diversity that goes with it, may not perform as expected.
Even though the model that was trained on the most diverse data available performed the most accurately, not all the models trained on less diverse data performed equally poorly. The worst-performing of the models trained on a single data source achieved an accuracy of just 74%, but the best-performing of these models increased that score by 8 percentage points. As noted above, these images differ in a variety of ways beyond the demographics of the people in the images – such as image quality, image resolution, photo orientation and other hard-to-quantify factors. This highlights a second challenge facing the users and designers of these systems: It is difficult to predict in advance how accurate these models will be based only on the data they are trained on. What we can predict, however, is that more diverse samples will tend to be more robust.
 We also examined how accurate each model was at identifying men and women and found that every model was at least somewhat more accurate at identifying one gender than it was at the other – even though every model was trained on equal numbers of images of women and men. These discrepancies are not apparent without doing this more detailed analysis: A model could be presented as 76% accurate without revealing that it only correctly classifies 60% of women, while correctly classifying 93% of men.
We also examined how accurate each model was at identifying men and women and found that every model was at least somewhat more accurate at identifying one gender than it was at the other – even though every model was trained on equal numbers of images of women and men. These discrepancies are not apparent without doing this more detailed analysis: A model could be presented as 76% accurate without revealing that it only correctly classifies 60% of women, while correctly classifying 93% of men.
At a broad level, these models tended to have more difficulty identifying women: Six of the eight (including the model that was built using the most diverse training data possible) were more accurate at identifying men than women. But two of the models were substantially more accurate at identifying women than men. And as with their overall accuracy, it is not entirely clear or predictable why certain models might be better at identifying men than women, or vice versa.
Implications for research on machine vision
It is important to note that there are several limitations to this study that should be kept in mind when interpreting the findings. First, the transfer learning approach we used builds on the information that already exists in pre-trained models. Second, because we created over 2,000 models for this project – and models trained using greater amounts of training data take longer to create – we used a relatively modest number of images to train each model. As a result, these models may be less accurate than systems that use more complex modeling strategies or more training data. Third, the images we used for training and testing are not meant to be representative of all the potential diversity in human faces. Rather, the goal of this project was to capture a set of images that was diverse enough to make meaningful comparisons about the way these types of systems learn about gender.
Lastly, it is important to note that these models were designed for a very specific task: to classify images of people as women or men based purely on their outward, physical characteristics. As noted above, our tool was only able to assign people to one of these two binary categories and was not able to account for people of other genders, including nonbinary individuals. It also had no fundamental understanding of gender or gender identity as concepts, and could not distinguish between someone’s physical appearance and their personal gender identity. And although the broad takeaways of this analysis are applicable to any sort of machine learning system, the specific results reported here may not generalize to other types of systems designed to classify gender, or those designed to do entirely different tasks.
But these caveats notwithstanding, this analysis can provide insights into the nature and limitations of this type of machine learning model. That these models are imperfect is to be expected. What may be less obvious is that they can be significantly less reliable for some groups than others – and that these differences may not necessarily be driven by intuitive or obvious factors. In general, it is important that these models be trained on data that captures the diversity of the situations they will encounter in real-world contexts, as much as that is possible. If the model will be called upon to operate on multiple ages, races and other qualities, for example, it is important that the model be trained on a similarly diverse training set. Ultimately, people who rely on the decisions these systems make should approach the results they produce with the knowledge that they may be hiding problems or biases that are hard to anticipate or predict in advance.
Please see the methodology for more details about how the Center conducted this analysis. We would like to thank Besheer Mohamed, Onyi Lam, Brian Broderick, Skye Toor, Adam Hughes, and Peter Bell for their invaluable contributions to this project. Information graphics by Selena Qian.
