Researchers from Pew Research Center used a multistep process to produce the findings of this study. These steps included:
- Creating eight distinct datasets from existing image corpora.
- Constructing a deep learning gender classification model that could be retrained repeatedly.
- Drawing random samples of equal-sized and gender-balanced images from each or all of the image corpora and training models using the images selected from just one sample.
- Tabulating the accuracy of the models trained using samples from each or all of the different image corpora and comparing the accuracy of each model.
Researchers also conducted an exploratory analysis for one of the models generated for the study using a technique known as image occlusion. Each of these steps is discussed in greater detail below.
Assembling training data
The data for this project comes from a variety of sources. We drew on seven distinct datasets of images (corpora), and generated an eighth composed of a mix of each of the seven. To gather this data, we located existing datasets used by researchers for image analysis. These include the “Labeled Faces in the Wild” (LFW) and “Bainbridge 10K U.S. Adult Faces” datasets.1 We also downloaded images of Brazilian politicians from a site that hosts municipal-level election results.
Researchers from the Center also created original lists of celebrities who belong to different minority groups and collected 100 images for each individual. The list of minority celebrities focused on famous black and Asian individuals. The list of black celebrities includes 22 individuals: 11 men and 11 women. The list of Asian celebrities includes 30 individuals: 15 men and 15 women. We repeated this procedure with a list of 21 celebrity seniors (11 men and 10 women) to incorporate images of older individuals.
We then compiled a list of the most-populous 100 countries and downloaded up to 100 images of men and women for each nation-gender combination, respectively (for example, “French man”).
Researchers isolated individuals’ faces from images including several people and removed irrelevant, blurry or obscured results. For more details about this collection process, read the methodology from the report “Gender and Jobs in Online Image Searches,” which used a model trained on this data.
Training and bootstrapping
We used a method called “transfer learning” to train each gender classification model, rather than using machine vision methods developed by an outside vendor. This method reuses information from existing or “pretrained” deep neural networks to speed up the training process (this process is described in more detail below). To generate the analysis used in this study, we compiled results from a total of 2,400 deep learning models. For each of the eight source image datasets, 300 models were estimated. Each model is based on a random sample from a source image dataset, so each iteration of the model was trained with a different mix of faces from that source image dataset.
A total of 10,906 images were used across all eight datasets. We split the data into different sets for training and testing – composed of 8,428 and 2,478 images respectively.2
To train each model, we drew mixes of images of individual faces from each of the source datasets, but required the total number of images to be the same and the gender distribution to be equal. Each model was trained using 1,204 sampled images of faces – 602 men and 602 women. Each training set was sampled from one of the seven collections listed above or a mix of all the source datasets. The same image could be sampled repeatedly. Each training set for a model trained on a mix of data sources contained 172 images of faces from each of the source datasets – 86 men and 86 women.
The performance for each model was obtained by measuring its accuracy on each image in the testing data. Each of the models was tested on the same dataset comprised of a random, gender-balanced mixture of 2,478 images of faces from the seven datasets listed above. Researchers used 354 images from each collection, 177 of men and 177 of women.
Gender classifier architecture
To generate the image classifiers used in this study, the research team relied on transfer learning, which involves recycling large pretrained neural networks (a popular class of machine learning models) for more specific classification tasks. The benefit of this technique was that lower layers of the pretrained neural networks often contained features that were useful across new image classification tasks, so researchers could build upon those features without starting from scratch. Specifically, researchers reused these pretrained lower layers and fine-tuned the top layers for their specific application – in this case, the gender classification task. Read this post on the Center’s Decoded blog for more details.
The specific pretrained network researchers used was VGG16, implemented in the popular deep learning Python package Keras. The VGG network architecture was introduced by Karen Simonyan and Andrew Zisserman in their 2014 paper “Very Deep Convolutional Networks for Large Scale Image Recognition.” The model is trained using ImageNet, which has over 1.2 million images and 1,000 object categories. VGG16 contains 16 weight layers that include several convolutional and fully connected layers. The VGG16 network has achieved a 90% top-5 accuracy in ImageNet classification.
Researchers began with the classic architecture of the VGG16 neural network as a base, then added one fully connected layer, one dropout layer and one output layer. The team conducted two rounds of training for each model: one for the layers added for the gender classification task (the custom model) and one for the upper layers of the VGG base model.
Researchers did not allow the VGG base weights to be updated during the first round of training, and restricted training during this phase to the custom top layers. The weights for the new layers were randomly initialized, so freezing the base weights prevented information contained within them from being destroyed. After 20 epochs of training on the custom model, the team unfroze four top layers of the VGG base and began a second round of training. For the second round of training, researchers implemented an early-stopping function. Early stopping checks the progress of the model loss (or error rate) during training, and halts training when validation loss value ceases to improve. This serves as both a timesaver and keeps the model from overfitting to the training data.
To help the system learn, the researchers added a step to manipulate or augment each training image slightly before the system would see it. This manipulation included zooming, clipping the sides, and rotating each image so the system would not learn on the basis of how pictures were composed, or on the basis of quirks in the training images – such as if faces of women happened to appear very close to other people in the images. The manipulation was done in a random, unpredictable way, so that even if the system was given the same image twice, it wouldn’t look identical each time. This step prevented the system from learning gender based on photo composition.
Modeling deep learning accuracy
 We collected the results of the models on the testing data such that each row corresponded to the result of a model on a single image. We calculated average accuracy of each model by gender. We then used multilevel ordinary least squares regression models to estimate the accuracy of a given model conditional on the source dataset used for training and the gender of the individual in the image.
We collected the results of the models on the testing data such that each row corresponded to the result of a model on a single image. We calculated average accuracy of each model by gender. We then used multilevel ordinary least squares regression models to estimate the accuracy of a given model conditional on the source dataset used for training and the gender of the individual in the image.
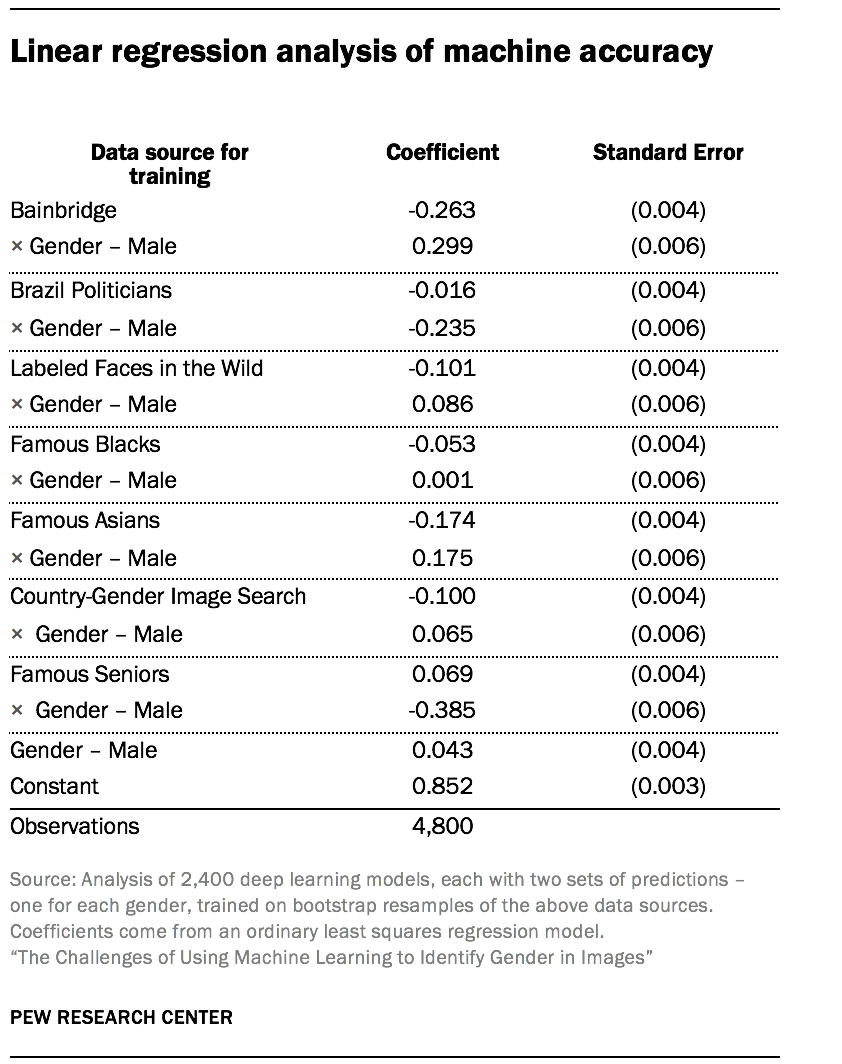
In order to create the estimates and standard errors for accuracy in the main essay, we calculated model predictions. The tables display the ordinary least squares estimates of accuracy based on the source dataset used for training, the gender of the individual in the image, and the multiplicative effect of the data source and the gender of the individual in the image.
Classifying occluded images
 In the interactive we use a method we call “occlusion” to get a sense of what the model is doing without delving into complicated math. As demonstrated in the interactive, this method involves covering (“occluding”) part of an image and having a model reclassify the occluded image. We systematically cover each part of each image by moving the occluded section across the image, following a grid. This allows us to map out the regions that, when covered, can change the model’s classification of an image.
In the interactive we use a method we call “occlusion” to get a sense of what the model is doing without delving into complicated math. As demonstrated in the interactive, this method involves covering (“occluding”) part of an image and having a model reclassify the occluded image. We systematically cover each part of each image by moving the occluded section across the image, following a grid. This allows us to map out the regions that, when covered, can change the model’s classification of an image.
In this interactive, we use one of the models trained in the process outlined above and included in the primary analysis. Specifically, we use the model trained on images from all seven data sources that achieved the highest overall accuracy of 90%. The exception to this is the demonstration before beginning the interactive, which used a different model.
