These results come from two Pew Internet tracking surveys. One was conducted between August 7-September 6. 2012 with 3,014 American adults (ages 18+). Among them were 2,581 the cell phone owners and the margin of error in the survey for findings among cell owners is plus or minus 2.1 percentage points. The second survey was conducted between March 15-April 3, 2012 among 2,254 adults, including 1,954 cell owners, and has a margin of error of plus or minus 2.4 percentage points. Both surveys were conducted on landline and cell phones and in English and Spanish.
DESIGN AND DATA COLLECTION PROCEDURES
Sample Design
A combination of landline and cell random digit dial (RDD) samples was used to reach a representative sample of all adults the United States who have access to either a landline or cellular telephone. Both samples were disproportionately-stratified to increase the incidence of African-American and Hispanic respondents. Within strata, phone numbers were drawn with equal probabilities. The landline samples were list-assisted and drawn from active blocks containing three or more residential listing while the cell samples were not list-assisted, but were drawn through a systematic sampling from dedicated wireless 100-blocks and shared service 100-blocks with no directory-listed landline numbers.
Contact Procedures
Interviews were conducted from August 7 to September 6, 2012. As many as 7 attempts were made to contact every sampled telephone number. Sample was released for interviewing in replicates, which are representative subsamples of the larger sample. Using replicates to control the release of sample ensures that complete call procedures are followed for the entire sample. Calls were staggered over times of day and days of the week to maximize the chance of making contact with potential respondents. Each phone number received at least one daytime call.
For the landline sample, interviewers asked to speak with either the youngest male or youngest female currently at home based on a random rotation. If no male/female was available at the time of the call, interviewers asked to speak with the youngest adult of the opposite sex. This systematic respondent selection technique has been shown to produce samples that closely mirror the population in terms of age and gender when combined with cell sample.
For the cell sample, interviews were attempted with the person who answered the phone. Interviewers first verified that the person was and adult and in a safe place before continuing with the interview.
WEIGHTING AND ANALYSIS
Weighting is generally used in survey analysis to adjust for effects of the sample design and to compensate for patterns of nonresponse that might bias results. The weighting was accomplished in multiple stages to account for the disproportionately-stratified sample, the overlapping landline and cell sample frames and differential non-response associated with sample demographics.
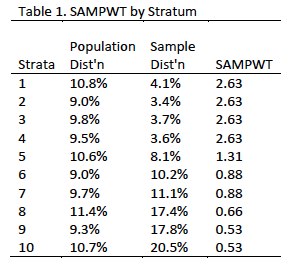
The first-stage of weighting compensated for the disproportionate sample design. This adjustment (called SAMPWT in the dataset) was computed by dividing the proportion of the population from each stratum by the proportion of sample drawn from the stratum. The landline and cell samples were drawn using the same relative sampling fractions within strata so the. Table 1 shows the SAMPWT values by strata.
The second stage of weighting corrected for different probabilities of selection based on the number of adults in each household and each respondents telephone use (i.e., whether the respondent has access to a landline, to a cell phone or to both types of phone).
The second-stage weight can be expressed as:

Both adjustments were incorporated into a first-stage weight that was used as an input weight for post-stratification. The data was raked to match sample distributions to population parameters. The African-American and White/Other samples were raked to match parameters for sex by age, sex by education, age by education and region. Hispanics were raked to match population parameters for sex by age, sex by education, age by education and region. In addition, the Hispanic group was raked to a nativity parameter.
The combined data was then raked to match population parameters for sex by age, sex by education, age by education, region, household phone use and population density. The white, non-Hispanic subgroup was also balanced by age, education and region. The telephone usage parameter was derived from an analysis of recently available National Health Interview Survey data. The population density parameter is county-based and was derived from Census 2000 data. All other weighting parameters were derived from the Census Bureau’s 2011 Annual Social and Economic Supplement (ASEC).
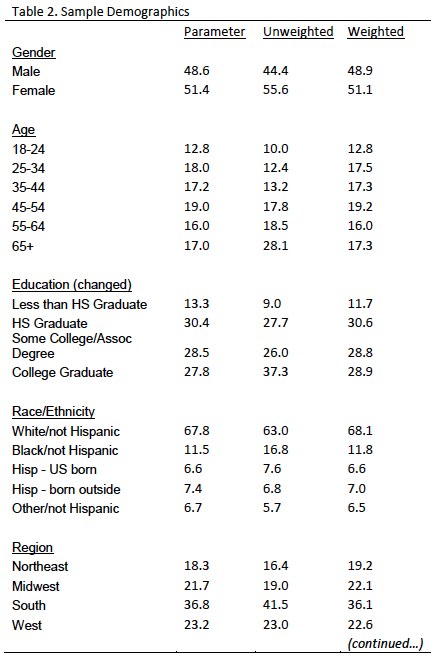
This stage of weighting, which incorporated each respondent’s first-stage weight, was accomplished using Sample Balancing, a special iterative sample weighting program that simultaneously balances the distributions of all variables using a statistical technique called the Deming Algorithm. The raking corrects for differential non-response that is related to particular demographic characteristics of the sample. This weight ensures that the demographic characteristics of the sample closely approximate the demographic characteristics of the population. Table 2 compares full sample weighted and unweighted sample demographics to population parameters.
Effects of Sample Design on Statistical Inference
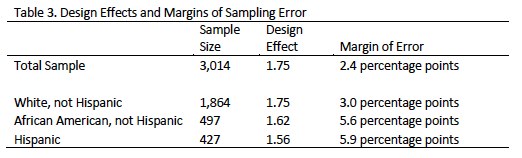
Post-data collection statistical adjustments require analysis procedures that reflect departures from simple random sampling. PSRAI calculates the effects of these design features so that an appropriate adjustment can be incorporated into tests of statistical significance when using these data. The so-called “design effect” or deff represents the loss in statistical efficiency that results from a disproportionate sample design and systematic non-response. The total sample design effect for this survey is 1.75.
PSRAI calculates the composite design effect for a sample of size n, with each case having a weight, wi as:
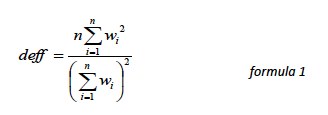
In a wide range of situations, the adjusted standard error of a statistic should be calculated by multiplying the usual formula by the square root of the design effect (vdeff ). Thus, the formula for computing the 95% confidence interval around a percentage is:
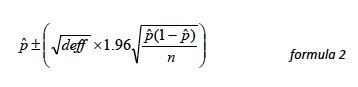
where p is the sample estimate and n is the unweighted number of sample cases in the group being considered.
The survey’s margin of error is the largest 95% confidence interval for any estimated proportion based on the total sample— the one around 50%. For example, the margin of error for the entire sample is ±2.4 percentage points. This means that in 95 out of every 100 samples drawn using the same methodology, estimated proportions based on the entire sample will be no more than 2.4 percentage points away from their true values in the population. It is important to remember that sampling fluctuations are only one possible source of error in a survey estimate. Other sources, such as respondent selection bias, question wording and reporting inaccuracy may contribute additional error of greater or lesser magnitude. Table 3 shows design effects and margins of error for key subgroups.
Response Rate
Table 4 reports the disposition of all sampled telephone numbers ever dialed from the original telephone number samples. The response rate estimates the fraction of all eligible sample that was ultimately interviewed.

