The Pew Hispanic Center conducted a public opinion study among people of Latino background or descent that was designed to elicit opinions on issues related to the 2010 Census. In order to fully represent the opinions of Latino people living in the United States, Social Science Research Solutions/SSRS conducted interviews with a statistically representative sample of the Latino population.
The study was conducted for The Pew Hispanic Center via telephone by SSRS, an independent research company. Interviews were conducted March 16-25, 2010 among a nationally representative sample of 1,003 Latino respondents age 18 and older. Of those respondents, 358 were Native born (including Puerto Rico) and 640 were Foreign born (excluding Puerto Rico). The margin of error for total respondents is +/-4.5 percentage points at the 95% confidence level. The margin of error for Native-born respondents is +/-7.5 percentage points at the 95% confidence level. The margin of error for Foreign-born respondents is +/-5.7 percentage points at the 95% confidence level.
Sample Design
The study employed landline and cell telephone exchanges and utilized a disproportionate stratified RDD sample of Latino Households. Additionally the sample frame utilized an Optimal Sample Allocation sampling technique. This technique provides a highly accurate sampling frame thereby reducing the cost per effective interview. In this case, we examine a list of all telephone exchanges within the contiguous United States and sort them based on Latino households. We then divide these exchanges into various groups, or strata, based on the coverage of Latino households per stratum.
Exchanges are then divided into various strata according to estimates of Latino household incidence and surname status within each NPA-NXX (area code and exchange) as provided by the GENESYS System – these estimates are derived from Claritas and are updated at the NXX level with each quarterly GENESYS database update. The basic procedure is to rank all NPA-NXXs in the U.S. by the incidence of Latino households. This array is then divided into five sets of NXXs, each with a different grouping of exchanges based on incidence and surname status.
Sample generation within each defined stratum utilized a strict EPSEM sampling procedure, providing equal probability of selection to every telephone number. Out of the national representative sample of 1003 Latino respondents, 203 interviews were conducted via cell phones. The following table provides a summary of the five strata employed in this study: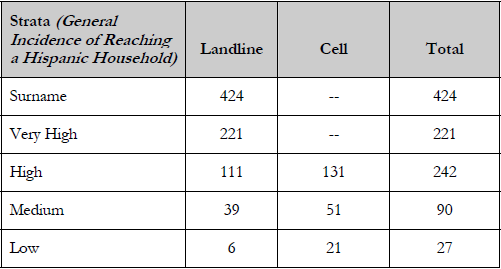
It is important to note that the existence of a surname strata does not mean this was a surname sample design. Using RDD sample, the telephone numbers were divided by whether they were found to be associated with or without a Latino surname. This was done simply to increase the number of strata (thereby increasing the control we have over the targeted sample) and to ease administration (allowing for more effective assignment of interviewers and labor hours).
For purposes of estimation, we employed an optimal sample allocation scheme. This “textbook” approach allocates interviews to a stratum proportionate to the number of Latino households, but inversely proportionate to the square root of the relative cost, where relative cost is a simple function of the incidence. Thus, the number of completed interviews increases from the lower incidence strata to the higher incidence strata.
Fielding and Data Collection
The field period for this study was March 16-25, 2010. The interviewing was conducted by ICR/International Communications Research in conjunction with SSRS/Social Science Research Solutions in Media, PA. All interviews were conducted using the Computer Assisted Telephone Interviewing (CATI) system.
For this survey, SSRS maintained a staff of Spanish-speaking interviewers whom, when contacting a household, were able to offer respondents the option of completing the survey in Spanish or in English. A total of 303 respondents were surveyed in English and 677 respondents interviewed in Spanish (and another 6 equally in both languages).
Weighting Procedures
Survey data were weighted to (1) adjust for the fact that not all survey respondents were selected with the same probabilities and (2) account for gaps in coverage in the survey frame. Pre-weights address the differential sampling rates described in section 1 of this appendix. In addition, the data was put through a post-stratification sample balancing procedure utilizing national 2009 estimates from the Census’ Current Population Survey, March Supplement, on gender, education, age, region, foreign/native born status, year of entry into the U.S., and Hispanic heritage.
