The Pew Hispanic Center conducted a public opinion survey among people of Latino background or descent that was designed to elicit opinions on issues related to health care. To fully represent the opinions of Latino people living in the United States, ICR conducted interviews with a statistically representative sample of Latinos so they could be examined nationally.
The study was conducted for the Pew Hispanic Center via telephone by ICR, an independent research company. Interviews were conducted from July 16 to September 23, 2007, among a nationally representative sample of 4,013 Latino respondents ages 18 and older. Of those respondents, 1,625 were native born (including Puerto Rico) and 2,378 were foreign born (excluding Puerto Rico). The margin of error for total respondents is +/-1.83 at the 95 percent confidence level. The margin of error for native-born respondents is +/-3.42 at the 95 percent confidence level. The margin of error for foreign-born respondents is +/- 2.11 at the 95 percent confidence level.
For this survey, ICR maintained a staff of Spanish-speaking interviewers whom, when contacting a household, were able to offer respondents the option of completing the survey in Spanish or in English. A total of 1,320 respondents were surveyed in English and 2,639 in Spanish (and 54 were interviewed equally in both languages).
Eligible Respondent
The survey was administered to any male or female age 18 and older who is of Latino origin or descent.
Field Period
The field period for this study was July 16 to September 23, 2007. The interviewing was conducted by ICR/International Communications Research in Media, Pennsylvania. All interviews were conducted using the Computer Assisted Telephone Interviewing (CATI) system. The CATI system ensured that questions followed logical skip patterns and that the listed attributes automatically rotated, eliminating “question position” bias.
Sampling Methodology
A stratified sample via the Optimal Sample Allocation sampling technique was used for the survey. By utilizing a stratified sample, one sample source was used to complete all interviews. This technique provides a highly accurate sampling frame, thereby reducing the cost per effective interview. In this case, we examined a list of all telephone exchanges within a target area (national, by state, etc.) and listed them based on concentration of Latino households. We then divided these exchanges into various groups, or strata.
Consequently, we used a disproportionate stratified RDD sample of Latino households. The primary stratification variables are the estimates of Latino household incidence and heritage in each NPA-NXX (area code and exchange) as provided by the GENESYS System—these estimates are derived from Claritas and are updated at the NXX level with each quarterly GENESYS database update. The basic procedure was to rank all NPA-NXXs in the U.S. by the incidence of Latino households. This produced strata that were called Very High, High, Medium, and Low Latino. These strata were then run against InfoUSA and other listed databases, and then scrubbed against known Latino surnames. Any “hits” were subdivided into a “surname” strata, with all other sample remaining in their originally designated strata. Overall, then, the study employed five strata. It is important to note that the existence of surname strata does not mean this was a surname sample design. The sample is RDD; telephone numbers were then divided by whether they were found to be associated with or without a Latino surname. This was done simply to increase the number of strata (thereby increasing the control we have to meet ethnic targets) and to ease administration (allowing for more effective assignment of interviewers and labor hours).
For purposes of estimation, we employed an optimal allocation scheme. This “textbook” approach allocates interviews to a stratum proportionate to the number of Latino HH, but inversely proportionate to the square root of the relative cost, the relative cost in this situation being a simple function of the incidence. As such, the number of completed interviews increases as you move from a lower incidence strata to higher incidence strata. Again, this is a known, formulaic approach to allocation that provides a starting point for discussions of sample allocation and associated costs. We have also provided estimates of the “effective sample size” associated with the resultant disproportionate allocation.
Weighting and Estimation
A two-stage weighting design was executed to ensure an accurate representation of the national Hispanic population.
The first stage takes the disproportionality of the stratified design and rebalances cases back to nationally representative counts of Hispanics. Thus, cases in strata that were under-sampled (for example, Low), attained weights in excess of 1, while cases in strata that were over-sampled (for example, Surname and Very High) were given weights under 1.
The second stage comprised of post-stratification weighting to nationally representative counts of Latinos by region, age, education, heritage, born in U.S./years in U.S., and gender. An industry standard ranking program was utilized to produce final post-stratification weights.
Response Rate
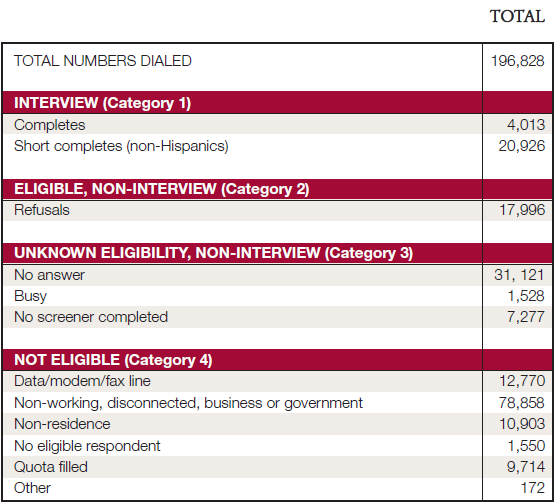
The overall response rate for this study was calculated to be 46.3 percent using AAPOR’s RR3 formula. Following is a full disposition of the sample selected for this survey: