(Related posts: How we adopted Kubernetes for our data science infrastructure, How we review code at Pew Research Center, How we built our data science infrastructure at Pew Research Center)
The research we do on Pew Research Center’s Data Labs team typically involves multiple members of our team working collaboratively on code that covers all aspects of a research project: data collection, processing, visualization and analysis.
Like many other data scientists, we manage our codebase using two popular tools: git and GitHub. However, both tools were primarily designed to help write code for software development — a process that differs in some ways from the process of writing code for data science. As a result, we’ve had to put significant effort into adapting the way we use git and GitHub and tailoring their concepts, tools and metaphors to our own team’s specific goals. For now at least, the approach we’ve settled on makes the way we write code more collaborative and the code itself more legible and reproducible.
In this post, we’ll describe how we use git and GitHub, the policies we developed to help modify these tools to the type of work we do, and some of the challenges we’ve faced along the way.
Version control with git and GitHub
The concept of version control is pretty intuitive. Even if you haven’t used a specialized version control tool before, you’ve likely used some process to keep track of changes and versions of a document when collaborating with others. Think of the track changes feature in Microsoft Word, or even something as simple as individual authors saving copies of a group document by appending the date or their initials to the file name. All of these approaches help team members keep track of what’s happening on a project, revert back to specific versions of a document or identify who made a particular change during the life of the file.
git solves the same problem in a more structured way and is the standard method for version control in software development. Though it can be daunting for beginners, git is just a tool that keeps track of the changes to files and allows you to navigate the history of versions of those files.
The mechanics of git are simple. Each co-author works separately on their own copy of the code. Periodically, they upload what they have written to a shared repository (similar to a shared folder) and download the changes that others have made. The repository takes care of consolidating all the different versions of the files, integrating changes and resolving conflicts. Think of it as similar to a live collaborative editor along the lines of Google Docs, but with more manual intervention.
GitHub is one of several sites that can be used to host the shared repositories that git needs. GitHub is well-known in the open-source community, and it offers a number of additional features, including an issue tracking system and a tool that helps structure the process of reconciling different versions of files.
While git and GitHub are commonly used in the field of data science, they are not nearly as universal as they are in the field of software development. In fact, in the early days of the Center’s Data Labs team, we didn’t use either tool. Instead, each researcher used whatever method of version control was most convenient for them. This flexibility came at the expense of easy collaboration. For example, without a common tool like git, getting new people up to speed on an existing project took a lot of time as they had to learn a new structure and process, as well as learn about the underlying topic and content of the project. We developed some of our most ambitious research projects this way, but we felt we needed to improve.
Goals and challenges of adopting git and GitHub
We started working with git and GitHub more consistently in late 2019. This transition helped us move toward achieving three objectives: greater consistency across projects, increased transparency and more effective collaboration. But it also meant dealing with questions about how some standard concepts in those tools would translate to the idiosyncrasies of our own computational social science work.
git and Github both were designed primarily with software development in mind. Typically, in software development, there is one “main” version of the code. This is the version used in production, which powers the actual application with which users interact. As developers add features and remove bugs, this “main” version evolves and goes through different versions that are periodically released. The process to make these changes often involves creating what, in the git parlance, are called branches: copies of the code on which a developer works separately — similar to having a personal copy of a shared Word document. These branches are eventually reconciled with the shared version (itself a branch commonly called main) through a process called a merge.
Some of our work at the Center — like our pewanalytics Python package — follows this software development model. But most of our code involves the data analysis side of data science.
Data analysis often requires a lot of exploratory work and frequent changes as a project gets re-scoped or a new idea emerges. There are many paths that the code can take, and adding to the “main” branch is not driven by an incremental process in pursuit of a clearly defined final product, as it is in software development. Instead, the stages of data analysis are defined by the writing and editing work that happens on a given report or blog post. As a result, collaboration in data science often takes the form of quick reviews that check the reasoning behind the analysis that another staff member is developing.
Consider branches, for instance. In software development, a branch is a distinct thread of development that includes an improvement to the version that is currently in production. Merging the branch means that the feature is complete and that it improves the product.
Analysis code is different. Often the changes are less about adding some new feature and more about continuing an exploration process: trying out different ways of visualizing the data, exploring new strategies to model the data or even abandoning ideas that turned out not to be fruitful. While these are tasks are similar, they do not fit all too well into the concepts of “adding a feature” or “fixing a bug.”
Thus, as we developed our approach for using git and GitHub, we had to find our own way of defining what a branch should include. In doing so, we tried to keep in mind the goals of using git and GitHub for social research: more transparent and effective collaboration, higher-quality analysis and code, and ultimately more reproducible research.
How we use git and GitHub
Let’s look at a few examples of how we think about some git and GitHub concepts in our day-to-day use at Pew Research Center. We expect some of these concepts to evolve as we find new challenges, but these are the current set of internal policies that establish how we use these tools.
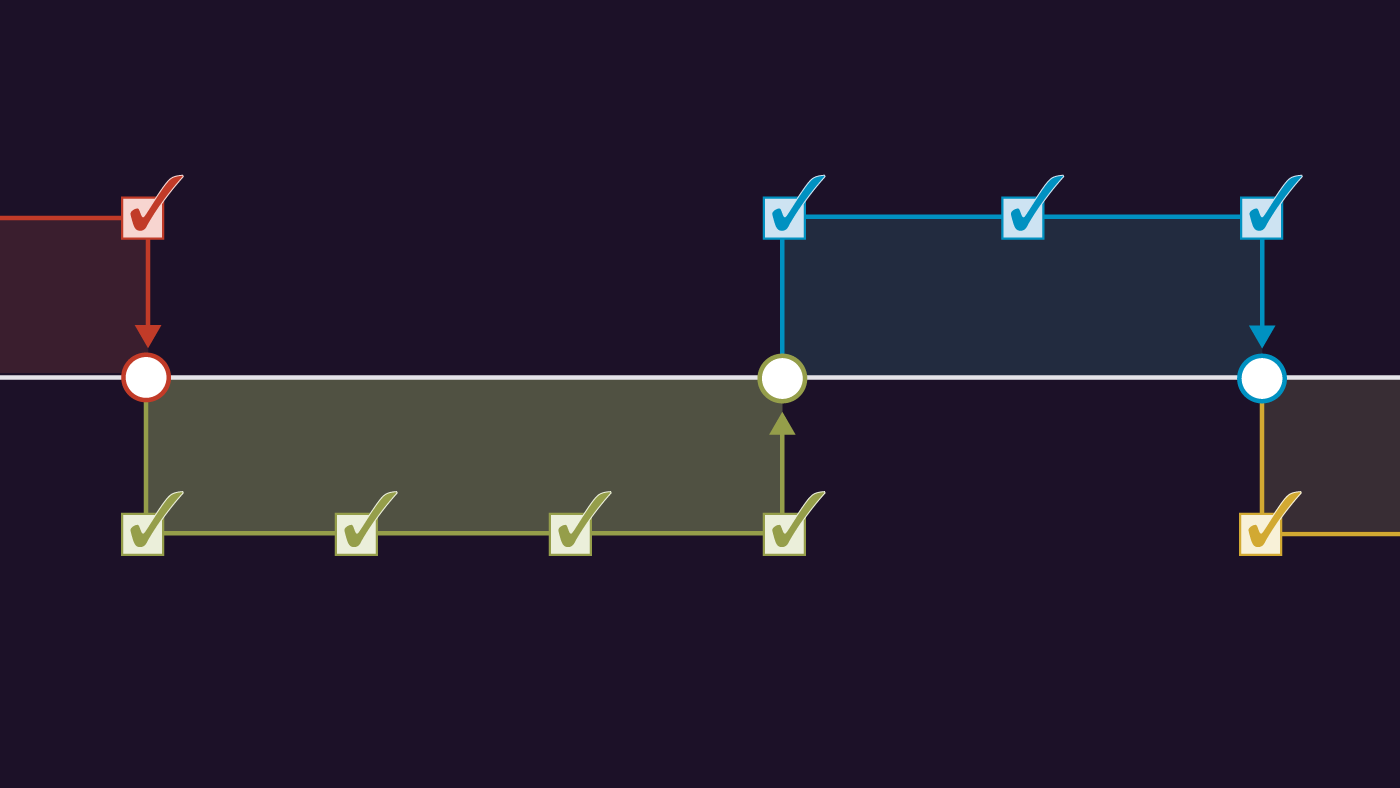
Let’s start with the most basic. The way git tracks changes over time is through a commit, which is a snapshot of the code at a point in time — similar to saving a copy of the file(s) you are working on. When creating a commit, the researcher has to write a message describing what the changes accomplish. It’s not uncommon for organizations to develop standards for what a good commit message looks like, and we did the same thing.
Having a high-quality log of commit messages makes our work much more transparent. New people joining a project can easily see the history of the work done thus far by going through the history of changes, and current collaborators can keep up with each other’s work in a similar way.
However, the more difficult question is not how to write a commit message but when to create one. What is the appropriate level of granularity in analysis code?
Sometimes what goes into a separate commit is obvious. For instance, maybe there is a problem caused by a call to a function that uses the wrong name. But more generally, when one is writing a script for data analysis, what is the best way to think about a discrete set of changes?
In our case, we approached the problem by thinking of a commit as an item on a to-do list. We can often clearly picture what we need to do when we need to, say, analyze a small survey. First, we need to read in and clean the data. Then we make descriptives of the variables we are interested in. Finally, we need to make production-quality tables and figures of the results we want to show. Each of these steps can be thought of as an item on a list of tasks that leads to a complete set of results, and each of them is a good candidate for a separate commit. The metaphor is admittedly ambiguous but, if nothing else, it gives team members an intuition about practices that are better avoided — such as thinking of commits as daily savepoints — and primes them to decompose their plans for a given analysis into roughly similar chunks.
Another git concept we needed to adapt was branching. As we said, in software engineering, branches are used to add improvements to an application in production that often lives in the “main” branch. In research, the code is never really in “production” until the corresponding report or blog post has been published. In the process of building an analysis, researchers try different things, some of which will work and some of which will not. But those are not features or bugs. We thought it made more sense to think of the main branch as containing a version of analysis on which all researchers agree, and to think of branches starting from “main” as individual researchers’ proposed additions. In a very literal way, we think of merging code into the main branch as a discussion between co-authors. Thus, if a commit is an item on a to-do list, a branch is a section of a to-do list that accomplishes a specific goal — something like “explore a method of analysis to address a particular question in our research” or “respond to feedback about the project.” These are blocks on which researchers can work separately and which can be understood as proposed additions to a collective analysis.
The key idea is that branches define natural points for the people working on a project to get together and discuss whether the analysis is moving in the right direction. Consequently, merging a branch into “main” is a key step in our quality control process. We take advantage of the way GitHub structures collaboration. To merge a branch, the researcher opens a pull request, which is an interface for requesting a review on the branch’s changes before putting them into a place that contains the results we all agree on. This step enforces the idea of code in the “main” branch being a consensus among researchers.
The type of consensus that is required changes over the life of a project. Some pull requests only need to be scrolled through and checked for appropriate file structure and documentation. Others need more robust checks. For example, a script that starts a time-intensive data collection is something you want to get right the first time. Our approach to branches and pull requests accounts for this variation by outlining what information needs to be communicated when opening a pull request, as opposed to using specific standards for review.
This process also ensures that no research decision can be made by a single person and that all the code is viewed by at least two people. One person developing alone will inevitably make mistakes that two or more people developing in tandem will catch. Two people discussing research decisions together, as they are implemented, also results in better designs. Early and consistent review also helps us write better, cleaner and more legible code, which, in turn, makes it much easier for someone in the future to re-run the code and replicate the analysis.
Incorporating branches and pull requests into our workflow changed the pace and style of all our work. The branch-pull request-review process slows things down, but we think sacrificing some time to ensure quality is worth it. This process encodes a method of collaborative decision-making between all the researchers in the team. It becomes less of a review to ensure the code is flawless and more of a quick check to prevent headaches at the end of the project. In general, it provides an opportunity to take a moment to check in with collaborators: to discuss a new idea for approaching an analysis, confirm that a method is working or just make sure everyone is up to date on the current status of the project.
Conclusions
As you can see, there is some vagueness in our approach, ranging from moderately ambiguous metaphors to deliberate room for flexibility. The core parts give clear expectations to researchers about the internal mechanics of how to collaborate with each other, as well as a shared language and metaphors to use when thinking about this process. As a team, we retain the ability to adjust our workflows as needed within the scope of our policy, which ensures that we create higher-quality code, regardless of specific implementation. This is why GitHub is such a powerful tool: It allows for a varied process to be consistently documented, made visible and standardized.
For social researchers, adopting a tool like git can feel intimidating and not worth the time. There’s also some appeal in letting researchers choose the workflow that suits them. After all, at the end of the day, we often value research mainly by its results. However, our experience is that using a common workflow simplifies communication, minimizes the cognitive burden that is required of all the collaborators (especially in a situation in which they all work on several different projects at the same time), and reduces the chances of mistakes. More importantly, it gives a structure for communication and collaboration with clearly defined checkpoints that bring the team together for discussion and review. git and GitHub are extremely effective at providing this structure because of both their core functionality and their flexibility. While your specific use cases might differ from ours, you can adapt them to your needs just as we have.
We expect our approach to git and GitHub to change over time as we refine our workflows, switch to new tools or discover that some of these things just aren’t working for us. However, we believe that the process of adopting git and consolidating internal metaphors into this current strategy has made it easier to work with and learn from one another, as well as improve our research overall. And the more researchers like us adopt and share similar policies, the more we can learn from our broader community about effective strategies, just as we learned from the open-source software development community.




