
When examining a collection of texts, researchers often want to get a sense of the differences in how certain words or phrases are used by different groups. For example, if we’re examining a collection of books, we might be interested in identifying phrases that distinguish particular authors or genres from one another. Similarly, if we’re looking at social media posts from members of Congress — to cite an actual line of research at Pew Research Center — we may want to hunt for linguistic patterns that distinguish Republicans from Democrats. In this post, we’re going to look at open-ended survey responses and attempt to identify words that distinguish different demographic groups in the United States from one another.
In 2018, the Center published a report that used two different surveys to examine where Americans find meaning and satisfaction in life. One survey used a traditional closed-format question, while the other prompted respondents to describe their sources of meaning in their own words. These latter responses were diverse and people responded enthusiastically to the question, writing 41 words on average (a lot for an open-ended question!). Ultimately, this yielded enough text to allow us to analyze Americans’ answers using computer-assisted methods, like semi-supervised topic modeling. But before turning to such time-consuming methods for our final analysis, we used a few other tools to conduct exploratory analysis and get a sneak peek into patterns in the data with minimal effort.
One of these tools was pointwise mutual information, or PMI, a quick and easy way to identify words that distinguish one group of documents from another. Speaking generally, PMI is an association metric that compares the relative frequency of two outcomes occurring together to the probability of either outcome occurring independently.
In text analysis, the outcomes in question are often both words, making PMI a measure of word association in a corpus. However, PMI can also be used to measure associations between words and document categories, which is how we used it here. With this application, the idea is to split a dataset into two categories — e.g., Republicans vs. Democrats, upper-income vs. lower-income respondents, religious vs. non-religious people, etc. — and identify words that co-occur with one of the two categories at a higher rate than we would expect if the words occurred independently in the data and had no relationship with the groups of people who used them.
What is pointwise mutual information, and how does it work?
We’ll need to get a bit more technical for a moment. The pointwise mutual information of a given word w to a category c is defined as follows:
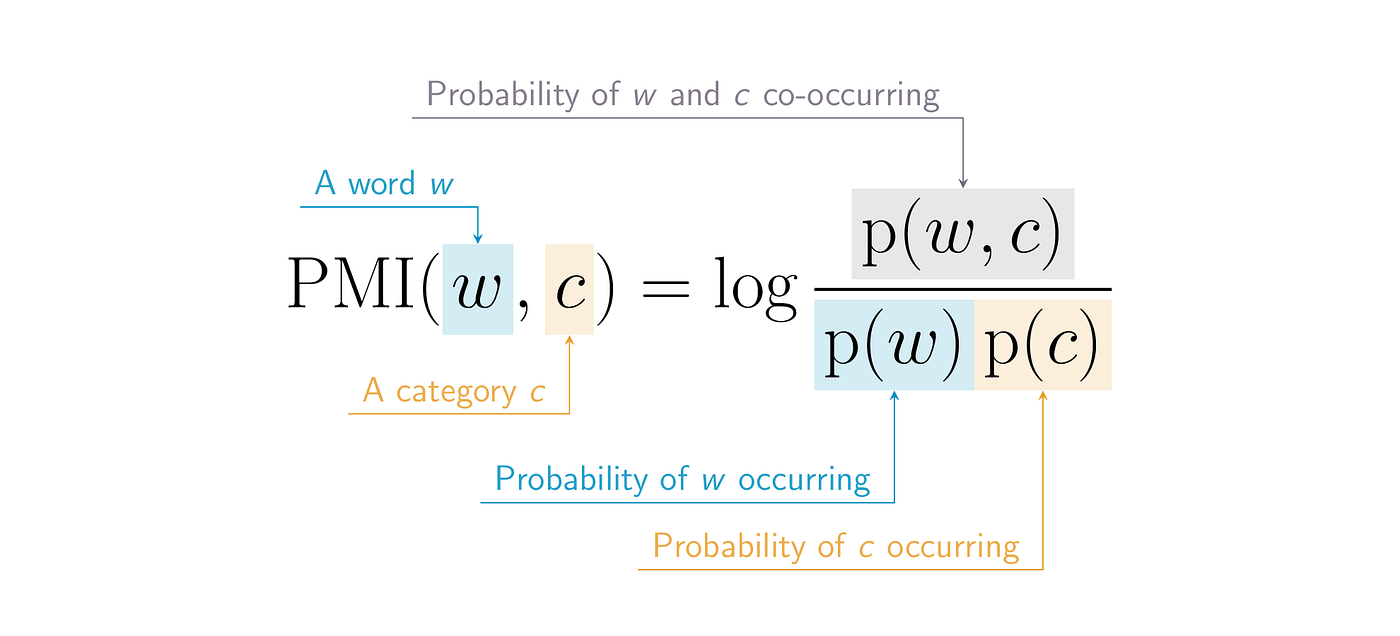
In this equation, the numerator p(w, c) is the probability that a document is both written by someone from category c and that it includes the word w — that is, that the word and the category co-occur in the real data we observe. In the denominator, p(w) is the probability of observing the word w in any category, while p(c) is the probability that out of all the documents, our given document is in the target category. Multiplying these two values together gives us the probability that the word w would appear in a document from category c completely by chance.
When the value of the fraction p(w, c) / p(w) p(c) is greater than one, it means the word w occurs in documents from category c more often than we would expect if the word and category were unrelated. Taking the logarithm of this value transforms the final measure so that a PMI value of zero indicates no association, a positive PMI indicates that documents from a given category are more likely to use a word and a negative PMI indicates that documents from that category are less likely to use it.
Let’s take a look at a quick example. Here’s a table that shows how many of our open-ended survey responses about the meaning of life used the words “church,” “hobbies” and “spouse,” broken out into religious and non-religious respondents:
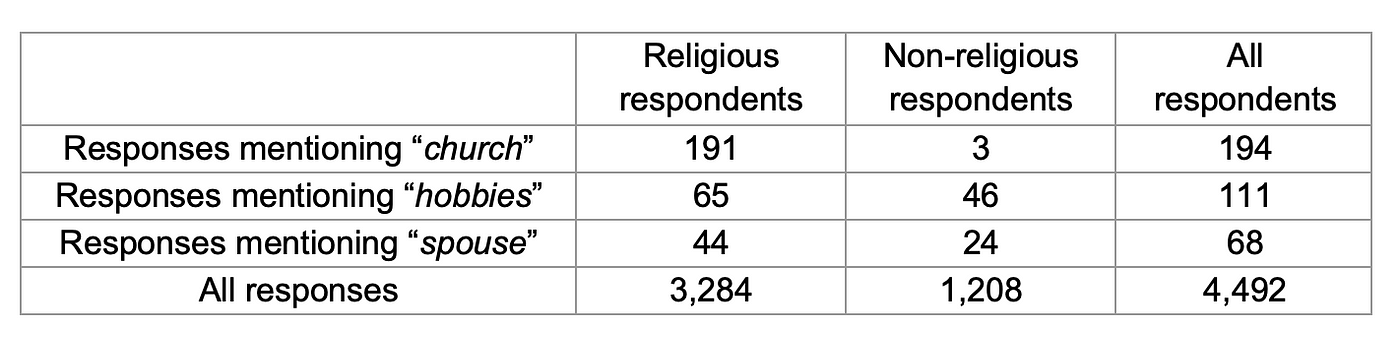
Let’s plug some of these counts into the equation for PMI and see if the use of the word “church” is distinctive to religious respondents, as we might expect:

First, let’s look at the numerator, p(w, c). We can calculate the probability that a document written by a religious person includes the word “church” by dividing that count (191) by the total number of responses (4,492) so that p(w, c) = 0.0425. The probability of any respondent using the word “church” is 194 / 4,492, so p(w) = 0.0432, and the probability of any respondent being religious is 3,284 / 4,492, so p(c) = 0.731. Multiplying those two values together gives us p(w) p(c), the probability that a respondent is both religious and used the word “church,” which is 0.0316. Since 0.0425 is greater than 0.0316, we can tell already that the value for PMI will be positive, but let’s go ahead and finish the calculation by dividing 0.0425 by 0.0316 and taking the logarithm, for a final value of 0.428. Here, we’re using a base 2 logarithm, but nothing substantial would change if we had used log base 10 or base e.
Doing the same calculations for other terms and categories, we can fill out the whole table with PMI values:

We can see that references to “church” were more distinctive to religious respondents, while references to “hobbies” or “spouse” were more distinctive to the responses of non-religious people.
Applying pointwise mutual information to research about the meaning of life
After working through the example in the section above, hopefully it’s becoming clear that what makes pointwise mutual information a useful tool is the fact that it gives us more than just information about how frequently different terms are used. Instead, it surfaces relative differences in the use of words between two groups, allowing us to identify words that are highly distinctive but not necessarily used all that frequently overall.
How we understand term distinctiveness can really matter for how we characterize texts or their authors. Let’s look at another example from those open-ended responses we collected on where Americans find meaning in their lives. Imagine we wanted to understand what kinds of language differentiate liberal Americans from conservatives. A straightforward place to start would be to count up all the different words used in each group’s responses (or term frequencies), and see what types of words are used most frequently by each group, as shown here:
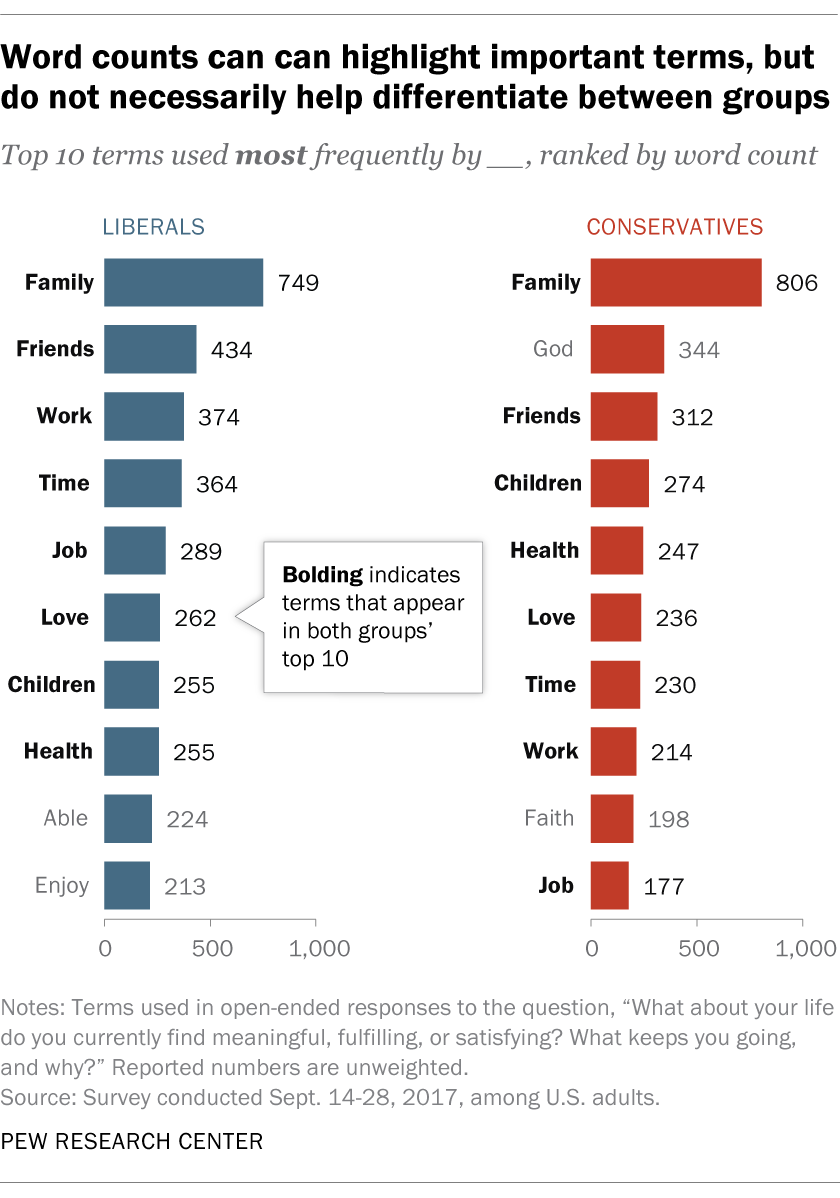
We can immediately see that both lists are capturing important terms that reflect where people find meaning in life, such their family and friends, their career or their health. When we look a little closer, though, we can see that there’s a lot of overlap between the words that liberals and conservatives use frequently. Eight of the top 10 most-used terms for liberals are also in the top 10 for conservatives, and the single most commonly used term for both groups is “family.” So while these simple term frequencies clearly highlight important terms that give us some insight into what Americans find meaningful, they aren’t doing very much to help us understand what differentiates liberals and conservatives.
Another approach would be to look at differences in term frequencies between the two groups. This is an intuitive idea: If conservatives use a word more than liberals do, it’s reasonable to think that word is more distinctive to conservatives. If we take the term frequency counts from one group and subtract the counts from the other group, we can get lists of the terms that are used more by one group than the other:
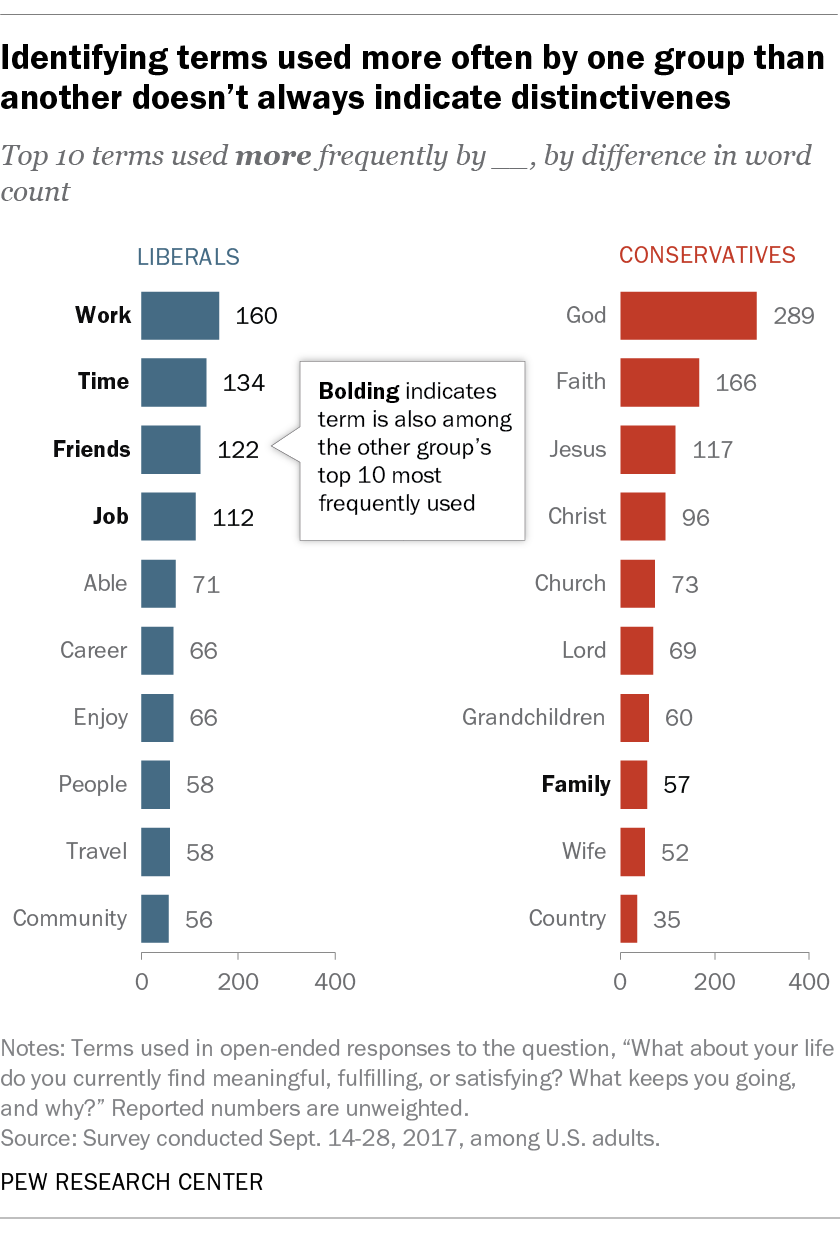
This gets us closer to a measure of distinctiveness and starts to show some interesting patterns. For instance, the top of the list for conservatives is populated by religious terms — “god,” “faith,” “church” — whereas the list for liberals has more career-related terms. But while term frequency differences can tell us that a word is used more by conservatives than liberals (or vice versa), it’s not immediately obvious which of these words are highly characteristic of a particular group and which are just common words that one group happened to use more than the other. Notice, for instance, that the word “family” appears again in the list of top 10 conservative words by term frequency difference. It would be a stretch to characterize “family” as a distinctively conservative word since we know from looking at the raw counts that it was the most common term in responses from both conservatives and liberals.
The problem here is that there is no baseline expectation of how frequently we should see a given term occurring in the first place. We can see that there were 57 more mentions of the word “family” among conservatives than among liberals, but is that actually a meaningful difference when compared to how frequently the word “family” was used across the whole collection of responses? This is the problem that PMI helps us address.
Let’s take a look at what these top 10 lists look like if we rank terms by PMI instead:
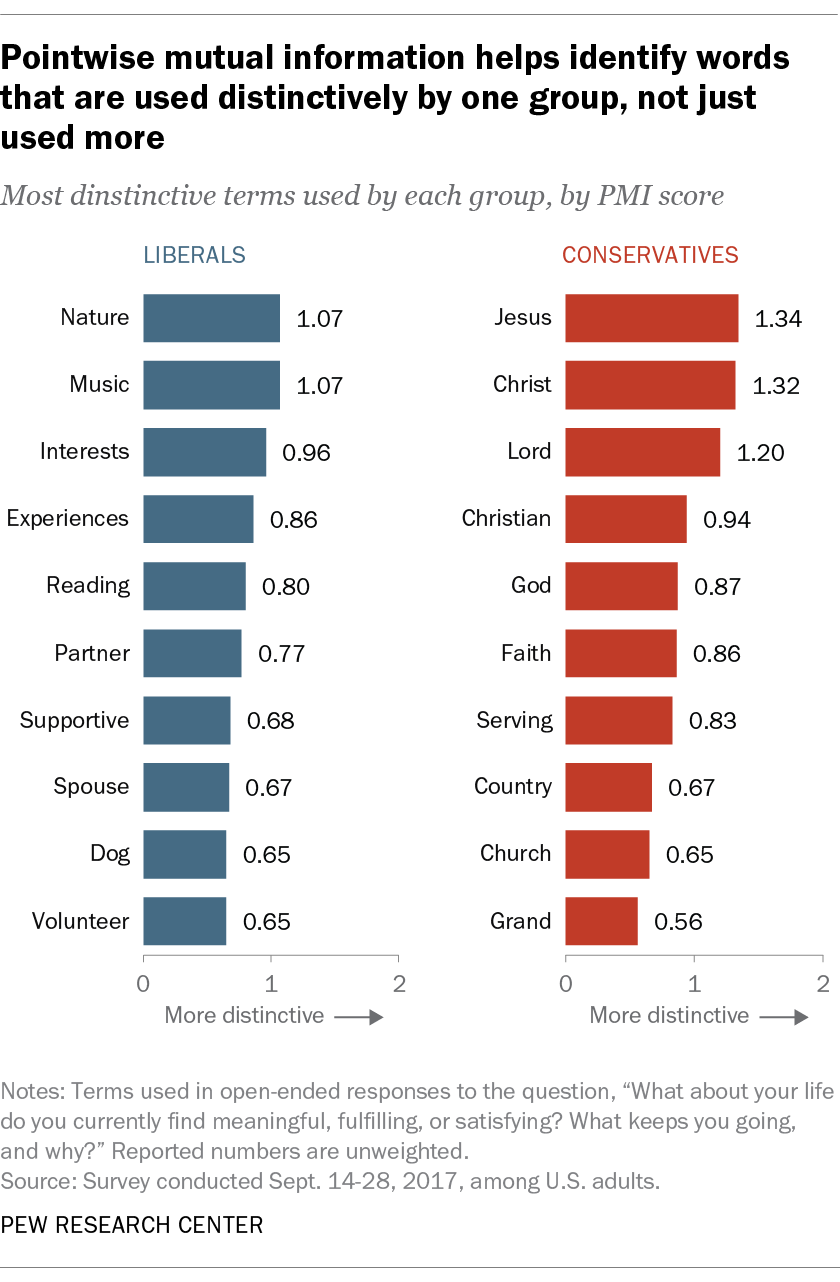
On the conservative side, we can see that many of the religious terms that were prominent on the term frequency differences list are still there, but common family-related terms like “family,” “grandchildren” or “wife” no longer appear. On the liberal side, some family-related terms remain in the PMI-ranked list, though it’s interesting to note that these are the gender-neutral terms “partner” and “spouse,” possibly highlighting linguistic differences in how liberals and conservatives refer to their significant others. We also see fewer career-related terms in this list, as many of those were also terms that appeared frequently in conservative responses. Instead, we see more of an emphasis on hobbies and creative pursuits with terms like “nature,” “music” and “reading.” This aligns closely with the findings from our 2018 report, where we observed through both open- and closed-ended questions that conservative Americans were much more likely than liberals to view their faith or spirituality as a key source of meaning, while liberals were more likely to derive meaning from creativity and social causes.
To highlight the analytical value that PMI can bring, let’s look more closely at how the list of terms changed for conservatives as we moved from one form of analysis to another. In the table below, we can see how the relative importance of certain terms changed as we moved from term frequency to differences in term frequency and, finally, to PMI:
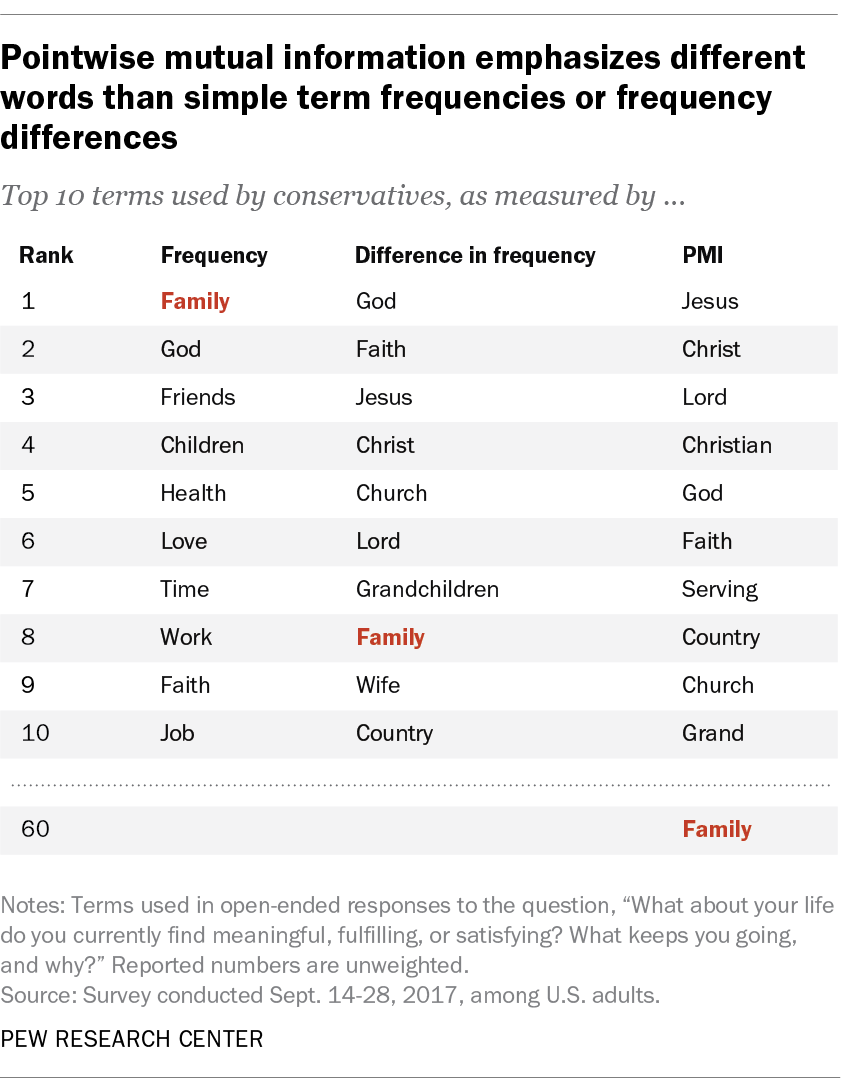
Using term frequency alone might lead a researcher to think that “family” is distinctive to conservatives’ responses when we know that’s not necessarily the case. In fact, the relative importance of the term drops to the rank of 8 when using differences in term frequency and all the way down to 60 when using pointwise mutual information. At the same time, many of the words that are the most distinctive for conservatives when using PMI don’t appear at all in the top 10 when we use term frequency.
Conclusion
Pointwise mutual information offers researchers a valuable exploratory tool that can be easily deployed to examine large collections of text, reveal interesting patterns and suggest directions for additional analysis. But like many other exploratory methods, PMI does have its limitations and not all of the differences it surfaces will wind up meaningful.
Still, if there are notable differences in the language used by two groups in your data, PMI provides a quick and easy way of identifying them for additional investigation. If you’d like to try this method out for yourself, our Python package for text processing and statistics utilities, pewanalytics, contains functions to calculate PMI. You can also find the full findings of our 2018 report on the meaning of life here.




